
Machine vision has changed drastically following its convergence with artificial intelligence. Traditional computer vision systems relied on predefined library functions and user-defined algorithms for all types of image processing tasks. Over the past decade, researchers have realized that human vision itself is inextricable from the human mind and learning. It was this realization that led to the use of deep learning networks in computer vision, such as Convolutional Neural Networks (CNN) or another deep learning method. Artificial Intelligence Vision is the new and sophisticated term for computer vision or machine vision.
The AI vision has been computationally expensive and complicated. As artificial intelligence advances and semiconductor chips become increasingly powerful, it is possible to implement deep learning networks in mobile processors and embedded systems as simple as 32-bit microcontrollers. This has moved computer vision models from clouds to edge devices, where computer vision can be used for embedded applications and a variety of narrow AI tasks. The AI vision market size is expected to reach US$48.6 billion in 2022 and reach US$144 billion by 2028. It is considered that computer vision will shape the world's new UX technology, where pocket computers on smartphones , gadgets, wearables and 'things' will have human-like vision and superior intelligence.
This article will discuss how next-generation computer vision systems work and why computer vision is increasingly important.
What is computer vision?
Computer vision is a field of artificial intelligence that deals with training computers to perceive and understand visual information from images, videos, and other visual inputs. AI vision is considered as natural as human vision. However, both are very different from each other. It is estimated that the human eye has a resolution of 576 megapixels, and this entire load of visual information is processed and analyzed by a highly complex network of brain neurons. Even supercomputers are far behind in computational speed compared to brain neurons, and the most advanced cameras do not have a resolution matching that of the human eye.
It is quite trivial to capture visual information in images, videos or live streams using cameras and sensors when it comes to computer vision. The real challenge is to derive meaningful insights and inferences from computationally captured visual data. This is where machine learning and deep learning are utilized. The real world is infinitely complex and varied, so a computer vision system can only be successful if it is capable of learning from visual information.
If human vision is an evolutionary masterpiece, computer vision has its advantages. Cameras can capture visual data better than human eyes. They can also capture visual information that cannot be accessed by human eyes, such as thermal imaging, medical scans and other imaging technologies. Computer vision systems can be designed to be more specific, precise and accurate than human vision. For example, deep facial recognition models have achieved a detection accuracy of 99.63% compared to human accuracy of 97.53%.
Computer vision tasks
Before learning how a computer vision system works, it is important to be familiar with common computer vision tasks. These simple visual perception tasks help to segregate a large-scale application into more straightforward problem statements. Each task requires some cognitive functionality for its execution.
- Image Classification: Image classification is a fundamental task in computer vision applications. It involves training a neural network to classify images by predefined categories. This usually involves sorting by specific objects. For example, this is an image of a cat, an image of a dog. If the classification has to be done between only two objects, it is called a binary classification problem. If classification has to be done between multiple objects, it is called multiclassification problem. In an image classification problem, the entire image is processed as a whole and a unique class/label is assigned to a particular image.
Image classification is a supervised learning problem. The model is trained to classify images using a set of already labeled/classified sample images. Once the training is done, a group of images must be classified by predefined labels/classes. An image classification model can easily be fine-tuned without sufficient training data. This is why transfer learning or knowledge transfer is often used in image classification models. An already trained machine learning model is reused to classify similar objects in the transfer learning method. This allows building scalable solutions with a small computational footprint. Image classification is often called object classification in AI jargon.

- Object detection is the first step in extracting features from an image. While image classification is limited to categorizing images into unique classes, object detection involves analyzing parts of the image to locate objects in them using bounding boxes. This is done by looking for class-specific details in an image, finding objects/classes in the image/video and labeling them by their class names. An image can contain multiple objects and an object detection model can look for multiple classes within an image.
Object detection is used in computer vision problems such as object identification, object verification, and object recognition. Compared to machine learning approaches like SIFT, HOG features and Haar features, deep learning models like RCNN, YOLO, SSD and MobileNet are more accurate and efficient in object detection tasks.

- Image segmentation: involves the exact masking of pixels that represent an object within an image. This requires discerning the object from its background and other objects in the image. Various machine learning and deep learning methods are used for image segmentation. Common machine learning methods applied to image segmentation include clustering, watershed, edge detection, region growing, region splitting and merging, and boundary. Typical deep learning models used for image segmentation include FPN, SegNet, PSPNet, and U-Net.
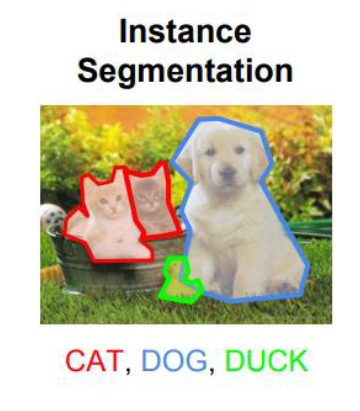
- Object landmark detection: This is similar to image segmentation. Instead of the object itself, in this task its context or landmark is identified. This involves discerning the background of the object in the image and assigning a class to the background rather than the object.
- Edge Detection: In this task, the boundaries of an object are detected in the image. Often this is a pre-processing step in image segmentation performed internally by a specialized edge detection filter within a convolution network. In many computer vision systems, this is part of image preprocessing, where edge detection is performed by applying a machine learning algorithm.

- Feature Extraction and Matching: Features are the internal indicators of an object. Feature extraction involves identifying the parts of an object. This is quite useful in object detection, pose estimation, and camera calibration problems. First, features of interest are detected in an image using edge detection or other feature extraction methods. This is followed by locating these resources with the help of local descriptors. Finally, features and their local descriptors are matched among a group of images for feature matching.
- Facial recognition: This type of object detection task in which the object to be detected or recognized is a unique human face. In a facial recognition task, features from an image are extracted, located, classified, and combined to derive a unique classification of the image itself. For example, facial features such as eyes, nose, mouth, ears are identified, located in the image, positions compared with an absolute mathematical model, and features are combined to perform the identification of a person.

- Optical Character Recognition: In this computer vision task, characters of a language must be identified in an image. These can be images of number plates or handwritten notes. OCR involves the segmentation of images into letters of a language and is usually accompanied by significant encoding of text for a given application.
- Image Restoration: This task involves restoring old images to regain their quality and/or adding color to old black and white photos. This is done by reducing additive noise in the image and performing inpainting of the image to restore damaged pixels or parts of the image. This may follow image colorization in black and white photos.

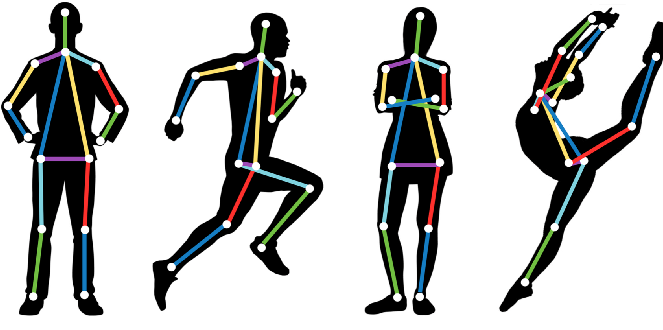
- Pose estimation: In this computer vision task, the pose of an object/human is identified. This involves identifying features, locating them in the image, and comparing the localized positions of the features to each other in the image. Common deep learning models used for pose detection include PoseNet, MeTRAbs, OpenPose, and DensePose.
- Video Motion Analysis: This computer vision task involves tracing the trajectory of an object in a video stream or camera and determining its speed, path, and movement. This very complicated task involves object detection, segmentation, localization, pose estimation and real-time tracking.
- Scene reconstruction: This is the most complex task in computer vision. It involves a 3D reconstruction of an object from 2D images or videos.
How computer vision works
A computer vision system has three levels of operation, as follows.
- Image acquisition: First, a computer vision system acquires images or videos or other forms of visual input (such as scans) from a camera or sensor. The captured images/video/streams are transferred to a stored computer system for further processing.
- Processing the images: The raw images need to be prepared to represent appropriate data. This is done by pre-processing images such as noise reduction, contrast adjustment, resizing and cropping the images. Most of these jobs are automated within a computer vision system. Some of these steps are already performed at the hardware level. In contrast, others are performed using suitable filters within a convolution network or applying suitable image processing functions to the captured raw data.
- Understanding images: This is the most important part of a computer vision system. It is the implementation of the actual computer vision task using a conventional style of image processing or with the help of a deep learning model.
Artificial intelligence has made the conventional style of image processing in computer vision obsolete. Deep learning network is a sure recipe for any computer vision problem.
The first step to understanding images is feature engineering. Captured images are converted into pixel matrices. Images take a lot of data for their computational representation, and color images require a good memory for their storage and interpretation within a model. Following a suitable computational presentation of the images, parts of the images are identified as objects using bubbles, edges and corners. This is a CPU-intensive and time-consuming process. This is why object detection is automated using transfer learning. Large companies working in computer vision and AI have shared their datasets and deep learning models as open source assets to facilitate and automate the process of detecting objects in images.
This is followed by training the convolution networks for the domain-specific tasks. Each computer vision application/task requires a specific dataset. For example, a traffic monitoring application will need a dataset to identify and classify vehicles. A cancer detection app will need a dataset of medical scans and reports. How a dataset is used to train a neural network model depends on the computer vision tasks involved in the specific application. Consequently, appropriate deep learning models are applied and associated performance metrics are monitored.
Challenges in computer vision
There are several challenges in computer vision applications. Often these challenges are related to image acquisition, feature engineering, or interpretation of visual data. For example, the difference in lighting will naturally compromise a computer vision application that depends on identifying the colors or image of the object. The presence of noise or unwanted features in images is another common problem in computer vision applications. Due to real-life circumstances, these unwanted features or noise are often added to images/videos. For example, images captured by a surveillance camera become blurry due to rain or dust storms. Likewise, objects superimposed on an image are always difficult to identify.
Another set of challenges appears in feature engineering selection. The physical world is so varied and versatile that choosing the appropriate features for extraction and matching in a given application can become a difficult task. For example, the same object looks different from different angles. The same object class can have a variety of colors and internal characteristics. For example, a cat may look different from different viewing angles; cats of the same breed have different fur colors and patches, and cats of different breeds have similar but different body features. Therefore, a deep learning model must receive images of the object from different angles and different variations to avoid underfitting. It is even possible for two objects to have similar characteristics and similarities, resulting in false similarities. This is why it takes thousands or millions of images to train a deep learning network to identify an object. This often involves detecting and matching hundreds of features to the same class/label.
Finally, a computer vision system can fail due to inadequate or insufficient interpretation of visual data. This often happens due to a lack of context or general intelligence in computer vision networks. After all, computer vision systems rely on identifying patterns in images. They can interpret images only in the context provided to them or within the limits of the set of features used in feature engineering. Deep learning networks can derive meaningful representations of objects/classes through convolution, but cannot generate contexts and references.
Conclusion
Convolutional neural networks have brought a revolution in the field of computer vision. Machine vision has also moved from the cloud to edge computing with advances in computer technology. Powered by artificial intelligence and sophisticated chip technology, computer vision is now applicable in many domains. The development of computer vision and artificial intelligence will continue hand in hand. Computer vision has already evolved beyond its limited capacity. Its future lies in new developments in the area of artificial general intelligence.






