
Aprenda a depurar aplicaciones Node.js de forma rápida y sencilla con esta guía completa. ¡Aproveche al máximo su experiencia de depuración de Node.js!

La depuración es una parte integral del proceso de desarrollo de software. Comprender sus estrategias y complejidades no sólo es esencial, sino que también constituye el núcleo de todos los esfuerzos de desarrollo. En el contexto de ofrecer servicios de desarrollo de Node JS, existen varias estrategias de depuración disponibles al crear aplicaciones de NodeJs.
En este tutorial, analizaremos estas metodologías y exploraremos cómo depurar aplicaciones NodeJs utilizando herramientas como la terminal, la declaración de depuración integrada de NodeJs, las herramientas de desarrollo de Chrome y Visual Studio Code.
Comenzaremos creando una aplicación básica con el siguiente escenario: Nuestra tarea es crear una aplicación que obtenga datos de alguna fuente (usaremos el marcador de posición JSON para esto) y manipule este conjunto de datos antes de guardarlos en un archivo JSON en el carpeta de la aplicación. Ahora, comencemos por crear nuestra aplicación lo más desacoplada posible para nuestra conveniencia.
Construyendo la aplicación
Crearemos una nueva carpeta llamada nodejs-debugging y luego ingresaremos el comando npm init -y dentro de esa carpeta para crear un archivo package.json. A continuación, instalaremos los paquetes Express, nodemon, axios y cors ejecutando npm i express axis cors nodemon. ExpressJS es un marco minimalista de NodeJS, axios nos ayudará a recuperar los datos correctamente, cors se asegurará de que no encontremos errores de cors y nodemon observará el servidor mientras le realizamos cambios.
Teniendo en cuenta que el sistema operativo que estamos usando es Linux, también ingresaremos los siguientes comandos para crear algunas carpetas y un index.js: mkdir controladores datos rutas y touch index.js. Antes de comenzar nuestro código, iremos al archivo package.json y lo cambiaremos como tal:
{
"nombre": "consejos-de-prueba-nodejs",
"versión": "1.0.0",
"descripción": "",
"principal": "index.js",
"guiones": {
"test": "echo \"Error: no se ha especificado ninguna prueba\" && salida 1",
"inicio": "nodo index.js",
"dev": "nodemon index.js"
},
"palabras clave": ,
"autor": "",
"licencia": "ISC",
"dependencias": {
"axios": "^1.4.0",
"cors": "^2.8.5",
"expreso": "^4.18.2"
}
}
Como puedes ver, en los scripts tenemos los comandos start y dev que ejecutan el proceso node y nodemon respectivamente. Cuando estamos en modo de desarrollo, queremos usar nodemon para nuestro propio bien. Ahora escribiremos un servidor express básico en el archivo index.js.
const expreso = requerir("expreso");
aplicación constante = expreso;
const cors = requerir("cors");
rutas constantes = require("./routes/posts.js");
puerto constante = proceso.env.PORT 5000;
aplicación.use(cors);
aplicación.get(" (req, res) => {
res.send("¡Hola mundo!");
});
valor constante = 5 - 3;
app.use("/publicaciones", rutas);
aplicación.listen(puerto, => {
console.log(`Aplicación de ejemplo escuchando en
});
Verás que hemos incluido algunas líneas adicionales como rutas, publicaciones y un valor. Nuestro servidor no funcionará ahora si ejecutamos npm run dev porque aún no tenemos esas rutas. La razón por la que lo hacemos de esta manera es modularizar nuestro código tanto como sea posible para que cuando queramos saber qué es, dónde y por qué, encontremos una estructura de carpetas administrada adecuadamente en lugar de un gran archivo index.js.
Escribiendo los controladores
Ahora, en nuestro directorio de controladores, crearemos un archivo controladores.js y agregaremos el siguiente fragmento dentro de él:
const axios = requerir("axios");
const fs = requerir("fs");
ruta constante = requerir("ruta");
const cripto = requerir("cripto");
const getPosts = async (req, res) => {
intentar {
respuesta constante = esperar axios.get(
"
{ parámetros: { _limit: 15 } }
);
const dataFolder = path.join(__dirname, "../data");
const archivo de datos = "posts.json";
si (!fs.existsSync(carpeta de datos)) {
fs.mkdirSync(carpeta de datos);
}
const postData = respuesta.data.map((publicación) => {
calificación constante = crypto.randomInt(1, 11); // Genera un número entero aleatorio entre 1 y 10, inclusive
devolver {
...correo,
clasificación,
};
});
fs.writeFileSync(path.join(dataFolder, dataFile), JSON.stringify(postData));
res.status(200).json(postData);
} captura (error) {
res.status(404).json({
mensaje: error.mensaje,
});
}
};
módulo.exportaciones = {
obtener publicaciones,
};
Repasemos lo que está sucediendo en este código.
Comenzamos importando los módulos necesarios, como axios para búsqueda, fs para sistema de archivos, ruta por ruta y cifrado para crear un número aleatorio. Entonces, con nuestra función getPosts asincrónica, enviamos una solicitud de obtención a " https://jsonplaceholder.typicode.com/posts " y limitamos la cantidad de objetos que recibiremos a 15. Este jsonplaceholder es una API ficticia que es muy útil. en desarrollo.
A continuación, especificamos dónde crearemos un archivo posts.json (carpeta de datos) y confirmamos que crearemos la carpeta si aún no existe para que no nos encontremos con un error por su ausencia. Entonces, para cada elemento que tenemos, creamos un número aleatorio entre 1 y 10 inclusive. Más tarde, utilizando el operador de extensión, agregamos este nuevo par clave/valor de clasificación aleatorio a los datos que ya tenemos. Para resumir, unimos todo y manejamos el error mediante la declaración catch.
Por último, exportamos la función getPosts para poder usarla en rutas.
Si todo va bien, deberíamos tener un archivo data/posts.json con 15 elementos dentro, que se ve así:
{
"ID de usuario" : 1,
"identificación" : 10,
"title" : "optio molestias id quia eum" ,
"body" : "quo et expedita modi cum officia vel magni\ndoloribus qui repudiandae\nvero nisi sit\nquos veniam quod sed accusamus veritatis error" ,
"calificación" : 6
},
{
"ID de usuario" : 2,
"identificación" : 11,
"título" : "et ea vero quia laudantium autem" ,
"cuerpo" : "delectus reiciendis molestiae occaecati non minima eveniet qui voluptatibus\naccusamus in eum beatae sit\nvel qui neque voluptates ut commodi qui incidunt\nut animi commodi" ,
"calificación" : 5
},
{
"ID de usuario" : 2,
"identificación" : 12,
"título" : "in quibusdam tempore odit est dolorem" ,
"cuerpo" : "itaque id aut magnam\npraesentium quia et ea odit et ea voluptas et\nsapiente quia nihil amet occaecati quia id voluptatem\nincidunt ea est distintivo odio" ,
"calificación" : 4
},
Aquí los campos userId, id, title y body se devuelven desde la API y hemos agregado el campo de calificación con un número aleatorio.
Ahora que hemos escrito nuestros controladores, es hora de escribir las rutas para que podamos importarlos a index.js y llamarlos mediante curl o una herramienta como Postman.
Escribiendo las rutas
Vayamos al directorio de rutas, creemos un archivo posts.js y peguemos el siguiente fragmento en él:
const expreso = requerir("expreso");
enrutador constante = express.Router;
const { getPosts } = require("../controllers/controllers.js");
enrutador.get(" getPublicaciones);
módulo.exportaciones = enrutador;
Aquí, al importar Express y usar su enrutador, estamos creando una ruta base para la función getPosts que obtenemos de controladores.js. También exportamos el enrutador. Ahora nuestro archivo index.js tiene sentido. Si enviamos una solicitud de obtención al archivo data/posts.json, se creará según lo especificado.
Depuración a través de Terminal y Watchers
Ahora que tenemos un proyecto en funcionamiento listo, podemos comenzar a jugar con la funcionalidad de depuración de NodeJs. La primera opción que tenemos es ejecutar node inspect index.js (o el archivo que queremos inspeccionar), y deberíamos recibir este mensaje en la terminal:
<Depurador escuchando en ws://127.0.0.1:9229/0d56efaa-fd7f-4993-be76-0437122ae1cf
< Para obtener ayuda, consulte:
<
conectando a 127.0.0.1:9229... ok
<Depurador adjunto.
<
Interrumpir al inicio en index.js:1
> 1 const expresar = requerir("expresar");
2 aplicación constante = expreso;
3 cors constantes = requerir("cors");
depurar>
Ahora estamos en el dominio de depuración. Podemos introducir determinadas palabras clave para realizar acciones.
- Al presionar c o cont continuará la ejecución del código hasta el siguiente punto de interrupción o hasta el final.
- Al presionar no siguiente se pasará a la siguiente línea.
- Al presionar s o paso se ingresará a una función.
- Al presionar se saldrá de una función.
- La pausa de escritura pausará el código en ejecución.
Si presionamos “n” varias veces, y después de ver el valor constante escribimos watch('value') y presionamos n una vez más, veríamos algo como esto en la terminal:
18 aplicación.escuchar(puerto, => {
depurar> observar ('valor')
depurar>n
interrupción en index.js: 18
Vigilantes:
0: valor = 2
16 app.use("/publicaciones", rutas);
Como puede ver, cuando especificamos que queremos observar el valor constante, el depurador JS nos muestra el resultado de la operación, y ese es el número 2. Este enfoque es similar a agregar declaraciones console.log en cierto sentido, pero sobre todo es útil. en un alcance muy pequeño. Imagínese si tuviéramos que presionar n cientos de veces para entrar en una cola, eso no sería muy productivo. Para ello tenemos otra opción.
Depuración usando la palabra clave debugger
Aquí cambiamos el archivo index.js agregando la palabra clave depurador después del valor constante:
const expreso = requerir("expreso");
aplicación constante = expreso;
const cors = requerir("cors");
rutas constantes = require("./routes/posts.js");
puerto constante = proceso.env.PORT 5000;
aplicación.use(cors);
aplicación.get(" (req, res) => {
res.send("¡Hola mundo!");
});
valor constante = 5 - 3;
//añadimos palabra clave depuradora después del valor constante
depurador;
app.use("/publicaciones", rutas);
aplicación.listen(puerto, => {
console.log(`Aplicación de ejemplo escuchando en
});
Cuando ejecutamos node inspect index.js nuevamente, ahora en lugar de presionar manualmente la tecla n repetidamente, podemos presionar c, y el depurador irá directamente a donde se declaró la palabra clave del depurador. Por lo tanto, podemos agregar nuestros observadores como queramos, como antes. A continuación se muestra un extracto del flujo de trabajo completo descrito:
sirius@sirius-20t8001ttx ~/c/a/testing-tips-nodejs (SIGINT)> nodo inspeccionar index.js
<Depurador escuchando en ws: //127.0.0.1:9229/03f908f6 -b6ce-4337-87b4-ed7c6eb2a027
<
< Para obtener ayuda, consulte: https://nodejs.org/en/docs/inspector
<
DE ACUERDO
<Depurador adjunto.
<
Interrumpir al inicio en index.js:1
> 1 const expresar = requerir("expresar");
2 aplicación constante = expreso;
3 cors constantes = requerir("cors");
//presionando c aquí
depurar>c
//salta directamente a la línea 15 donde se declaró la palabra clave depurador
interrupción en index.js: 15
13
14 valor constante = 5 - 3;
>15 depuradores;
dieciséis
17 app.use("/publicaciones", rutas);
//agregando observador al valor constante
depurar> observar ('valor')
//va a la siguiente línea
depurar>n
interrupción en index.js: 17
// podemos ver a nuestros observadores
Vigilantes:
0: valor = 2
15 depurador;
dieciséis
>17 app.use("/publicaciones", rutas);
18
19 aplicación.listen(puerto, => {
depurar>
Chrome DevTools: el depurador de Node JS
Ahora cambiemos un poco nuestra estrategia y usemos otras herramientas de depuración. Imaginemos que cometimos un error en nuestros controladores. En lugar de escribir const rating = crypto.randomInt(1, 11); , escribimos const rating = crypto.randomInt(-11, 11); .
Ahora, como escribimos -11 en lugar de 1, las calificaciones también tendrán números negativos y no queremos eso. Ejecutamos nuestra aplicación, enviamos la solicitud de obtención y notamos que las calificaciones incluyen números negativos. Si bien este es un caso bastante obvio, imagina que estamos tratando con una función enorme que llama a otras funciones que llaman a otras funciones, y necesitamos descubrir dónde surge el problema. Si utilizamos navegadores Chrome o basados en Chromium, tenemos a nuestra disposición Chrome Dev Tools para comprobar el estado de la aplicación en cualquier punto de depuración de una forma que sea más fácil de seguir visualmente. Para comenzar, detengamos nuestro servidor y cambiemos la función postData en ontrollers.js de esta manera:
const postData = respuesta.data.map((publicación) => {
calificación constante = crypto.randomInt(-11, 11); // Genera un número entero aleatorio entre 1 y 10, inclusive
console.log(calificación);
depurador;
devolver {
...correo,
clasificación,
};
});
Luego volvemos a ejecutar nuestra aplicación con un comando ligeramente diferente => nodo –inspeccionar index.js. Ahora, con las líneas incluidas antes de la palabra clave inspeccionar, tenemos acceso al servidor a través de nuestro navegador. Vaya al siguiente enlace => chrome://inspect/#devices. Aquí deberíamos ver algo como esto:
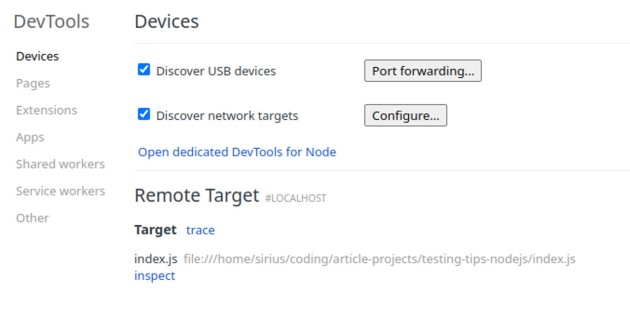
Aquí, haremos clic en "Abrir DevTools dedicado para Node", lo que abrirá algo como esto:
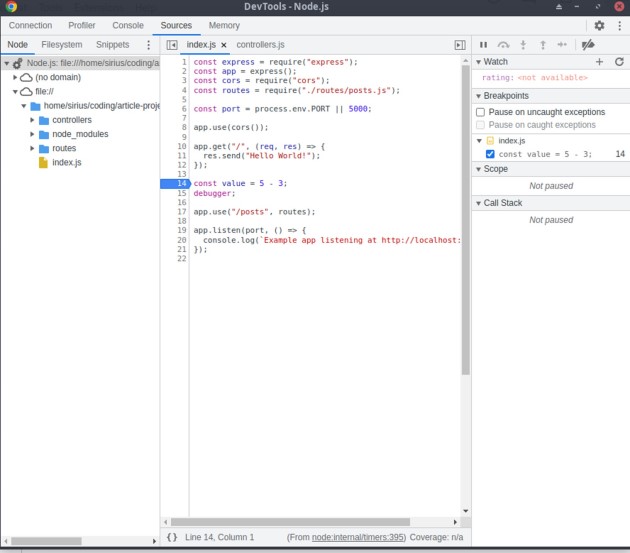
Están sucediendo muchas cosas aquí. Como puedes ver, a la izquierda podemos cambiar los directorios y archivos como queramos e inspeccionar el código. A la derecha podemos definir observadores, las palabras clave que buscará el depurador. Allí ingresamos “calificación”, porque queremos ver el valor de las calificaciones. Si no hubiéramos incluido también la palabra clave debugger en el archivo controladores.js, no podríamos ver el valor de las calificaciones. Ahora, si abrimos Postman y reenviamos una solicitud de obtención a /posts, deberíamos aparecer una pantalla como esta:
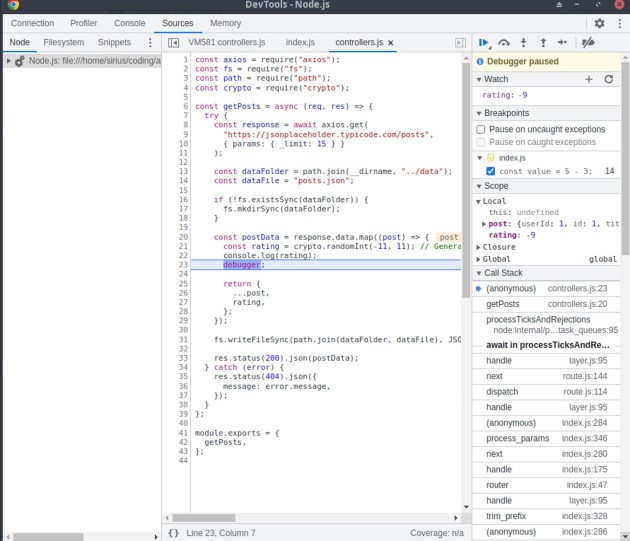
Ahora ves que el valor de calificación es -9. Podemos inferir que hicimos algo mal en nuestro código que causó este comportamiento y verificar si la constante de clasificación acepta valores entre -11 y 11. Ahora, si hiciéramos clic en F8 para reanudar la ejecución, veríamos un valor diferente como este:
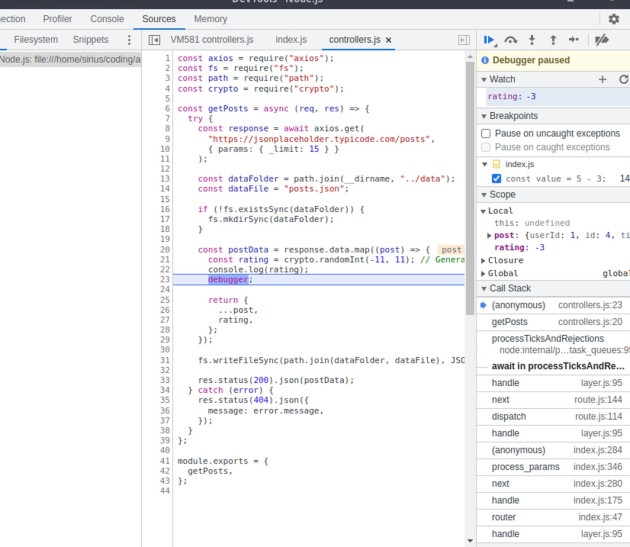
Además, si comprobamos qué está pasando con Postman, veremos que la ejecución aún está en curso porque la aplicación se detiene en la palabra clave depuradora. Ahora también podemos hacer lo mismo directamente en VS Code.
Depuración con Visual Studio Code
Ahora es el momento de depurar el código directamente en VS Code. Lo primero que debemos hacer es cerrar nuestro servidor de vigilancia y abrir VS Code. Allí, en el lado izquierdo, debería haber una sección Ejecutar y Depurar. Si pulsamos sobre él se mostrará una pantalla como esta:
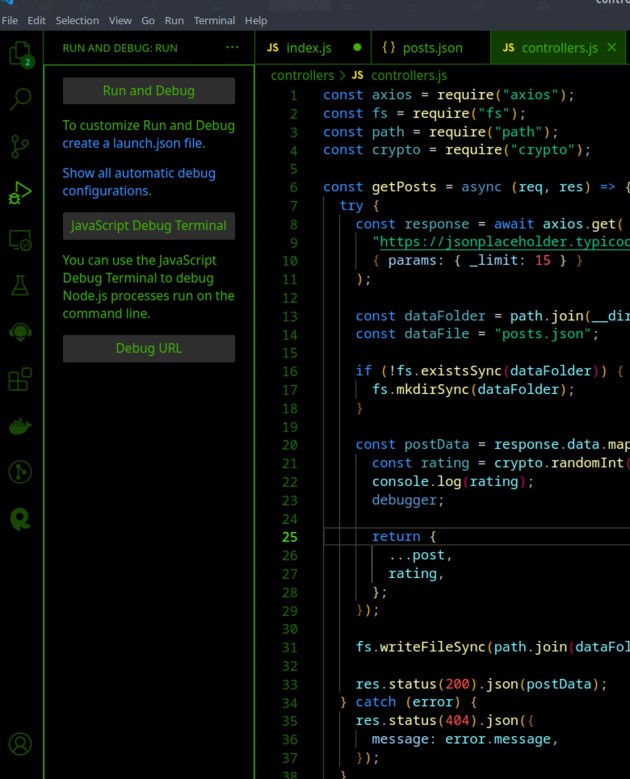
Aquí elegiremos "crear un archivo launch.json" y luego en la línea de comando, si se abre, elegiremos "NodeJs" y nos creará un archivo launch.json que se verá así:
{
// Utilice IntelliSense para conocer posibles atributos.
// Pase el cursor para ver descripciones de atributos existentes.
// Para más información visite:
"versión": "0.2.0",
"configuraciones": (
{
"tipo": "nodo",
"solicitud": "lanzamiento",
"nombre": "Programa de lanzamiento",
"omitir archivos": (
"<nodo_interno>/**"
),
"programa": "${workspaceFolder}/index.js"
}
)
}
Ahora, si hacemos clic en iniciar en la esquina superior izquierda, o esta vez hacemos clic en F5, se iniciará el servidor de inspección. Si enviamos una solicitud de obtención a través de Postman, nos enviará a la palabra clave depurador en el archivo controladores.js:
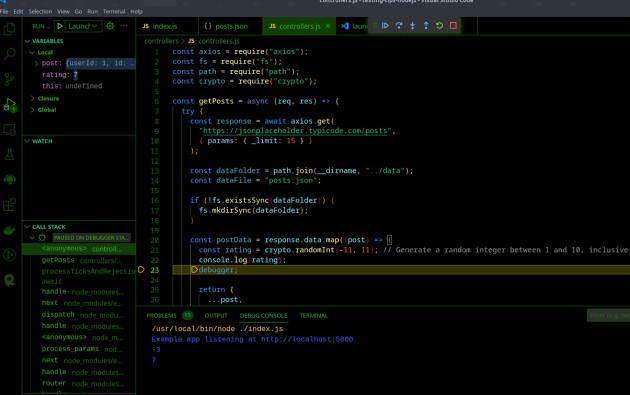
Aquí también, al igual que Chrome Dev Tools, cada actualización daría como resultado un valor de calificación diferente. Usando esta herramienta y técnica podemos observar nuevamente y ver que hay algún problema con las calificaciones y luego debemos verificar qué está causando el problema.
Conclusión
A lo largo de este tutorial, exploramos varias estrategias para depurar aplicaciones NodeJS, destacando la importancia de los métodos más allá de las simples declaraciones console.log. Como forma de garantizar un proceso de desarrollo más fluido, puede resultar ventajoso subcontratar el desarrollo de NodeJS. Al hacerlo, podrá aprovechar las habilidades y la experiencia de los expertos en el campo, mejorando así la calidad y eficiencia generales de su proyecto.
Si le gustó este artículo, consulte nuestras otras guías a continuación;
- Cambiar la versión del nodo: una guía paso a paso
- Caché de Node JS: aumento del rendimiento y la eficiencia
- Libere el poder de los microservicios Node.JS
- Liberando el poder de Websocket Nodejs
- Los mejores editores de texto y Node JS IDE para el desarrollo de aplicaciones
Preguntas frecuentes
¿Cuáles son algunas de las mejores prácticas a seguir al depurar en Node.js?
Durante una sesión de depuración en Node.js, algunas de las mejores prácticas a seguir incluyen obtener una comprensión integral del depurador integrado y usarlo de manera efectiva. También es beneficioso incorporar herramientas externas como Chrome DevTools y VS Code en su configuración de depuración. En lugar de depender en gran medida de "console.log", considere reemplazarlo con herramientas de registro y depuración más sólidas siempre que sea posible. También es fundamental familiarizarse con las opciones 'inspeccionar' e 'inspeccionar-brk' disponibles en Node.js, que le permiten detener la ejecución del código javascript y recorrerlo metódicamente. También se recomienda incorporar linters en su configuración de depuración, ya que ayudan a identificar errores de codificación comunes desde el principio.
Por último, la práctica de redactar pruebas unitarias sigue siendo invaluable; No sólo ayuda a identificar errores, sino que también funciona de forma preventiva para evitar posibles problemas futuros.
¿Cómo puedo utilizar las herramientas de depuración integradas en Node.js para mejorar mi proceso de depuración?
Node.js está equipado con una sólida herramienta de depuración incorporada que puede amplificar notablemente su proceso de depuración. Para utilizar esta herramienta, inicie el depurador ejecutando su aplicación con las opciones de línea de comandos 'inspect' o 'inspect-brk', seguidas de la ruta a su script. Por ejemplo, usar 'aplicación de inspección de nodo' pondría su aplicación en modo de depuración. La opción 'inspect-brk', por otro lado, permite que su script se inicie pero pausa la ejecución hasta que se conecta un cliente de depuración, lo que le brinda la posibilidad de depurar el proceso de inicialización de su script.
Una vez que el cliente de depuración esté operativo, le permitirá revisar meticulosamente su código, investigar variables y evaluar expresiones. Al incorporar la palabra clave 'depurador' en su código, puede establecer puntos de interrupción que pausan la ejecución de su script, lo que le permite examinar de cerca el estado del programa. Esto se puede monitorear cómodamente en la consola de depuración. Si prefiere una interfaz gráfica para una experiencia más intuitiva, tanto el depurador Chrome DevTools como VS Code brindan soluciones viables. Su panel de depuración puede conectarse a su sesión de depuración de Node, lo que garantiza un proceso de depuración fácil de usar que representa visualmente el estado de su código y el flujo de ejecución.
¿Puede darnos un ejemplo de una técnica avanzada de depuración de Node.js y cómo utilizarla de forma eficaz?
Una técnica avanzada de depuración de Node.js implica el uso del proceso de depuración 'post-mortem'. En este método, se crea un 'volcado de núcleo', o una instantánea detallada del estado de la aplicación, cuando la aplicación sufre un fallo u otro evento crítico. El análisis de estos volcados de núcleo, que se pueden lograr utilizando herramientas como 'llnode' y 'mdb_v8', ofrece información detallada sobre lo que condujo al problema. La generación de un volcado de núcleo se puede iniciar desde el mensaje de depuración utilizando las opciones integradas de Node.js o módulos externos como 'node-report' al ejecutar su aplicación, por ejemplo, 'node app'.
Cuando su aplicación falla o se activa manualmente, 'node-report' generará un archivo de resumen de diagnóstico que es fácil de entender. Este archivo presenta información vital sobre la pila de JavaScript, la pila nativa, las estadísticas del montón, la información del sistema y el uso de recursos, que pueden ser indispensables al depurar problemas difíciles de reproducir.
Aunque esta técnica avanzada requiere un conocimiento profundo del lenguaje y el tiempo de ejecución, su uso efectivo puede exponer la causa subyacente de errores complicados, especialmente aquellos relacionados con el rendimiento y fallas del sistema.
Fuente: BairesDev







