La visión artificial ha cambiado drásticamente tras su convergencia con la inteligencia artificial. Los sistemas tradicionales de visión por computadora se basaban en funciones de biblioteca predefinidas y algoritmos definidos por el usuario para todo tipo de tareas de procesamiento de imágenes. Durante la última década, los investigadores se han dado cuenta de que la visión humana en sí misma es inseparable de la mente y el aprendizaje humanos. Fue esta comprensión la que llevó al uso de redes de aprendizaje profundo en visión por computadora, como las redes neuronales convolucionales (CNN) u otro método de aprendizaje profundo. Artificial Intelligence Vision es el término nuevo y sofisticado para la visión por computadora o visión artificial.
La visión de la IA ha sido computacionalmente costosa y complicada. A medida que avanza la inteligencia artificial y los chips semiconductores se vuelven cada vez más potentes, es posible implementar redes de aprendizaje profundo en procesadores móviles y sistemas integrados tan simples como microcontroladores de 32 bits. Esto ha trasladado los modelos de visión por computadora de las nubes a dispositivos periféricos, donde la visión por computadora se puede utilizar para aplicaciones integradas y una variedad de tareas específicas de IA. Se espera que el tamaño del mercado de la visión por IA alcance los 48.600 millones de dólares en 2022 y los 144.000 millones de dólares en 2028. Se considera que la visión por computadora dará forma a la nueva tecnología UX del mundo, donde las computadoras de bolsillo, los teléfonos inteligentes, los dispositivos, los dispositivos portátiles y las cosas. 'Tendrá una visión humana y una inteligencia superior.
Este artículo analizará cómo funcionan los sistemas de visión por computadora de próxima generación y por qué la visión por computadora es cada vez más importante.
¿Qué es la visión por computadora?
La visión por computadora es un campo de la inteligencia artificial que se ocupa de entrenar computadoras para percibir y comprender información visual a partir de imágenes, videos y otras entradas visuales. La visión de la IA se considera tan natural como la visión humana. Sin embargo, ambos son muy diferentes entre sí. Se estima que el ojo humano tiene una resolución de 576 megapíxeles, y toda esta carga de información visual es procesada y analizada por una red muy compleja de neuronas cerebrales. Incluso las supercomputadoras están muy por detrás en velocidad de cálculo en comparación con las neuronas del cerebro, y las cámaras más avanzadas no tienen una resolución que coincida con la del ojo humano.
Es bastante trivial capturar información visual en imágenes, vídeos o transmisiones en vivo utilizando cámaras y sensores cuando se trata de visión por computadora. El verdadero desafío es obtener conocimientos e inferencias significativas a partir de datos visuales capturados computacionalmente. Aquí es donde se utilizan el aprendizaje automático y el aprendizaje profundo. El mundo real es infinitamente complejo y variado, por lo que un sistema de visión por computadora sólo puede tener éxito si es capaz de aprender a partir de información visual.
Si la visión humana es una obra maestra de la evolución, la visión por computadora tiene sus ventajas. Las cámaras pueden capturar datos visuales mejor que los ojos humanos. También pueden capturar información visual a la que los ojos humanos no pueden acceder, como imágenes térmicas, exploraciones médicas y otras tecnologías de imágenes. Los sistemas de visión por computadora pueden diseñarse para que sean más específicos, precisos y exactos que la visión humana. Por ejemplo, los modelos de reconocimiento facial profundo han logrado una precisión de detección del 99,63% en comparación con la precisión humana del 97,53%.
Tareas de visión por computadora
Antes de aprender cómo funciona un sistema de visión por computadora, es importante estar familiarizado con las tareas comunes de visión por computadora. Estas simples tareas de percepción visual ayudan a segregar una aplicación a gran escala en planteamientos de problemas más sencillos. Cada tarea requiere de alguna funcionalidad cognitiva para su ejecución.
- Clasificación de imágenes: La clasificación de imágenes es una tarea fundamental en las aplicaciones de visión por computadora. Implica entrenar una red neuronal para clasificar imágenes por categorías predefinidas. Por lo general, esto implica clasificar por objetos específicos. Por ejemplo, esta es la imagen de un gato, la imagen de un perro. Si la clasificación debe realizarse sólo entre dos objetos, se denomina problema de clasificación binaria. Si la clasificación debe realizarse entre varios objetos, se denomina problema de multiclasificación. En un problema de clasificación de imágenes, la imagen completa se procesa como un todo y se asigna una clase/etiqueta única a una imagen en particular.
La clasificación de imágenes es un problema de aprendizaje supervisado. El modelo está entrenado para clasificar imágenes utilizando un conjunto de imágenes de muestra ya etiquetadas/clasificadas. Una vez realizado el entrenamiento, se debe clasificar un grupo de imágenes mediante etiquetas/clases predefinidas. Un modelo de clasificación de imágenes se puede ajustar fácilmente sin suficientes datos de entrenamiento. Es por eso que el aprendizaje por transferencia o la transferencia de conocimientos se utiliza a menudo en los modelos de clasificación de imágenes. Un modelo de aprendizaje automático ya entrenado se reutiliza para clasificar objetos similares en el método de aprendizaje por transferencia. Esto permite construir soluciones escalables con una huella computacional pequeña. La clasificación de imágenes a menudo se denomina clasificación de objetos en la jerga de la IA.

- La detección de objetos es el primer paso para extraer características de una imagen. Si bien la clasificación de imágenes se limita a categorizar imágenes en clases únicas, la detección de objetos implica analizar partes de la imagen para localizar objetos en ellas mediante cuadros delimitadores. Esto se hace buscando detalles específicos de la clase en una imagen, encontrando objetos/clases en la imagen/video y etiquetándolos por sus nombres de clase. Una imagen puede contener varios objetos y un modelo de detección de objetos puede buscar varias clases dentro de una imagen.
La detección de objetos se utiliza en problemas de visión por computadora, como identificación de objetos, verificación de objetos y reconocimiento de objetos. En comparación con enfoques de aprendizaje automático como SIFT, funciones HOG y funciones Haar, los modelos de aprendizaje profundo como RCNN, YOLO, SSD y MobileNet son más precisos y eficientes en las tareas de detección de objetos.

- Segmentación de imágenes: implica el enmascaramiento exacto de los píxeles que representan un objeto dentro de una imagen. Esto requiere discernir el objeto de su fondo y de otros objetos en la imagen. Se utilizan varios métodos de aprendizaje automático y aprendizaje profundo para la segmentación de imágenes. Los métodos comunes de aprendizaje automático aplicados a la segmentación de imágenes incluyen agrupación, cuenca hidrográfica, detección de bordes, crecimiento de regiones, división y fusión de regiones y límites. Los modelos típicos de aprendizaje profundo utilizados para la segmentación de imágenes incluyen FPN, SegNet, PSPNet y U-Net.
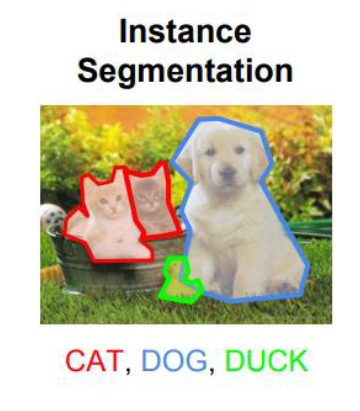
- Detección de puntos de referencia de objetos: esto es similar a la segmentación de imágenes. En lugar del objeto en sí, en esta tarea se identifica su contexto o hito. Esto implica discernir el fondo del objeto en la imagen y asignar una clase al fondo en lugar del objeto.
- Detección de bordes: en esta tarea, los límites de un objeto se detectan en la imagen. A menudo, este es un paso de preprocesamiento en la segmentación de imágenes realizado internamente por un filtro de detección de bordes especializado dentro de una red convolucional. En muchos sistemas de visión por computadora, esto es parte del preprocesamiento de imágenes, donde la detección de bordes se realiza aplicando un algoritmo de aprendizaje automático.

- Extracción y coincidencia de características: las características son los indicadores internos de un objeto. La extracción de características implica identificar las partes de un objeto. Esto es bastante útil en problemas de detección de objetos, estimación de pose y calibración de cámaras. Primero, las características de interés se detectan en una imagen mediante detección de bordes u otros métodos de extracción de características. A esto le sigue la localización de estos recursos con la ayuda de descriptores locales. Finalmente, las características y sus descriptores locales se comparan entre un grupo de imágenes para hacer coincidir las características.
- Reconocimiento facial: este tipo de tarea de detección de objetos en la que el objeto a detectar o reconocer es un rostro humano único. En una tarea de reconocimiento facial, las características de una imagen se extraen, ubican, clasifican y combinan para derivar una clasificación única de la imagen en sí. Por ejemplo, se identifican rasgos faciales como ojos, nariz, boca, orejas, se ubican en la imagen, se comparan posiciones con un modelo matemático absoluto y se combinan rasgos para realizar la identificación de una persona.

- Reconocimiento óptico de caracteres: en esta tarea de visión por computadora se deben identificar los caracteres de un idioma en una imagen. Pueden ser imágenes de matrículas o notas escritas a mano. OCR implica la segmentación de imágenes en letras de un idioma y suele ir acompañado de una codificación significativa de texto para una aplicación determinada.
- Restauración de imágenes: esta tarea implica restaurar imágenes antiguas para recuperar su calidad y/o agregar color a fotografías antiguas en blanco y negro. Esto se hace reduciendo el ruido aditivo en la imagen y realizando un pintado de la imagen para restaurar píxeles o partes de la imagen dañados. Esto puede deberse a la coloración de la imagen en fotografías en blanco y negro.

- Estimación de pose: en esta tarea de visión por computadora, se identifica la pose de un objeto/humano. Esto implica identificar características, ubicarlas en la imagen y comparar las posiciones localizadas de las características entre sí en la imagen. Los modelos de aprendizaje profundo comunes utilizados para la detección de poses incluyen PoseNet, MeTRAbs, OpenPose y DensePose.
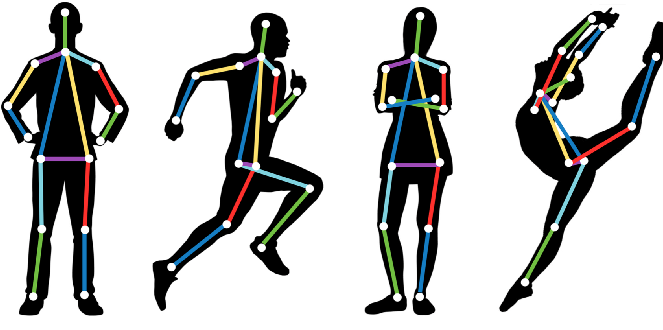
- Análisis de movimiento de video: esta tarea de visión por computadora implica rastrear la trayectoria de un objeto en una transmisión de video o cámara y determinar su velocidad, trayectoria y movimiento. Esta tarea tan complicada implica detección, segmentación, localización, estimación de pose y seguimiento en tiempo real de objetos.
- Reconstrucción de escenas: esta es la tarea más compleja en visión por computadora. Se trata de una reconstrucción 3D de un objeto a partir de imágenes o vídeos 2D.
Cómo funciona la visión por computadora
Un sistema de visión por computadora tiene tres niveles de operación, como se muestra a continuación.
- Adquisición de imágenes: primero, un sistema de visión por computadora adquiere imágenes o videos u otras formas de información visual (como escaneos) de una cámara o sensor. Las imágenes/videos/transmisiones capturadas se transfieren a un sistema informático almacenado para su posterior procesamiento.
- Procesamiento de las imágenes: las imágenes sin procesar deben prepararse para representar los datos apropiados. Esto se hace preprocesando imágenes, como reducción de ruido, ajuste de contraste, cambio de tamaño y recorte de las imágenes. La mayoría de estos trabajos están automatizados dentro de un sistema de visión por computadora. Algunos de estos pasos ya se realizan a nivel de hardware. Por el contrario, otros se realizan utilizando filtros adecuados dentro de una red convolucional o aplicando funciones de procesamiento de imágenes adecuadas a los datos sin procesar capturados.
- Comprensión de imágenes: esta es la parte más importante de un sistema de visión por computadora. Es la implementación de una tarea de visión por computadora real utilizando un estilo convencional de procesamiento de imágenes o con la ayuda de un modelo de aprendizaje profundo.
La inteligencia artificial ha dejado obsoleto el estilo convencional de procesamiento de imágenes en visión por computadora. La red de aprendizaje profundo es una receta segura para cualquier problema de visión por computadora.
El primer paso para comprender las imágenes es la ingeniería de características. Las imágenes capturadas se convierten en matrices de píxeles. Las imágenes requieren una gran cantidad de datos para su representación computacional, y las imágenes en color requieren una buena memoria para su almacenamiento e interpretación dentro de un modelo. Tras una presentación computacional adecuada de las imágenes, partes de las imágenes se identifican como objetos mediante burbujas, bordes y esquinas. Este es un proceso que consume mucho tiempo y consume mucha CPU. Es por eso que la detección de objetos se automatiza mediante el aprendizaje por transferencia. Las grandes empresas que trabajan en visión por computadora e inteligencia artificial han compartido sus conjuntos de datos y modelos de aprendizaje profundo como activos de código abierto para facilitar y automatizar el proceso de detección de objetos en imágenes.
A esto le sigue el entrenamiento de las redes convolucionales para las tareas específicas del dominio. Cada aplicación/tarea de visión por computadora requiere un conjunto de datos específico. Por ejemplo, una aplicación de seguimiento del tráfico necesitará un conjunto de datos para identificar y clasificar vehículos. Una aplicación de detección de cáncer necesitará un conjunto de datos de exploraciones e informes médicos. La forma en que se utiliza un conjunto de datos para entrenar un modelo de red neuronal depende de las tareas de visión por computadora involucradas en la aplicación específica. En consecuencia, se aplican modelos de aprendizaje profundo apropiados y se monitorean las métricas de desempeño asociadas.
Desafíos en la visión por computadora
Existen varios desafíos en las aplicaciones de visión por computadora. A menudo, estos desafíos están relacionados con la adquisición de imágenes, la ingeniería de características o la interpretación de datos visuales. Por ejemplo, la diferencia en la iluminación naturalmente comprometerá una aplicación de visión por computadora que depende de la identificación de los colores o la imagen del objeto. La presencia de ruido o características no deseadas en las imágenes es otro problema común en las aplicaciones de visión por computadora. Debido a circunstancias de la vida real, estas características o ruidos no deseados a menudo se agregan a las imágenes/videos. Por ejemplo, las imágenes capturadas por una cámara de vigilancia se vuelven borrosas debido a la lluvia o las tormentas de polvo. Asimismo, los objetos superpuestos a una imagen siempre son difíciles de identificar.
Otro conjunto de desafíos aparece en la selección de ingeniería de características. El mundo físico es tan variado y versátil que elegir las características apropiadas para la extracción y comparación en una aplicación determinada puede convertirse en una tarea difícil. Por ejemplo, el mismo objeto se ve diferente desde diferentes ángulos. La misma clase de objeto puede tener una variedad de colores y características internas. Por ejemplo, un gato puede verse diferente desde diferentes ángulos de visión; Los gatos de la misma raza tienen diferentes colores y manchas de pelaje, y los gatos de diferentes razas tienen características corporales similares pero diferentes. Por lo tanto, un modelo de aprendizaje profundo debe recibir imágenes del objeto desde diferentes ángulos y diferentes variaciones para evitar un ajuste insuficiente. Incluso es posible que dos objetos tengan características y similitudes similares, lo que da como resultado falsas similitudes. Es por eso que se necesitan miles o millones de imágenes para entrenar una red de aprendizaje profundo para identificar un objeto. Esto a menudo implica detectar y hacer coincidir cientos de características con la misma clase/etiqueta.
Finalmente, un sistema de visión por computadora puede fallar debido a una interpretación inadecuada o insuficiente de los datos visuales. Esto sucede a menudo debido a una falta de contexto o de inteligencia general en las redes de visión por computadora. Después de todo, los sistemas de visión por computadora se basan en la identificación de patrones en imágenes. Pueden interpretar imágenes sólo en el contexto que se les proporciona o dentro de los límites del conjunto de características utilizadas en la ingeniería de características. Las redes de aprendizaje profundo pueden derivar representaciones significativas de objetos/clases mediante convolución, pero no pueden generar contextos ni referencias.
Conclusión
Las redes neuronales convolucionales han supuesto una revolución en el campo de la visión por ordenador. La visión artificial también ha pasado de la nube a la informática de punta con los avances en la tecnología informática. Impulsada por inteligencia artificial y tecnología de chips sofisticada, la visión por computadora ahora es aplicable en muchos dominios. El desarrollo de la visión por ordenador y la inteligencia artificial seguirán de la mano. La visión por computadora ya ha evolucionado más allá de su capacidad limitada. Su futuro pasa por nuevos desarrollos en el ámbito de la inteligencia general artificial.