
Aprenda como depurar aplicativos Node.js de forma rápida e fácil com este guia completo. Aproveite ao máximo sua experiência de depuração do Node.js!

A depuração é parte integrante do processo de desenvolvimento de software. Compreender as suas estratégias e complexidades não é apenas essencial, mas também constitui o núcleo de todos os esforços de desenvolvimento. No contexto de oferta de serviços de desenvolvimento Node JS, existem várias estratégias de depuração disponíveis durante a construção de aplicativos NodeJs.
Neste tutorial, discutiremos essas metodologias e exploraremos como depurar aplicativos NodeJs usando ferramentas como o terminal, a instrução de depurador integrada do NodeJs, as ferramentas de desenvolvimento do Chrome e o Visual Studio Code.
Começaremos criando uma aplicação básica com o seguinte cenário: Nossa tarefa é construir uma aplicação que busque dados de alguma fonte (usaremos espaço reservado JSON para isso) e manipule esse conjunto de dados antes de salvá-los em um arquivo JSON em a pasta do aplicativo. Agora, vamos começar construindo nosso aplicativo da forma mais desacoplada possível para nossa conveniência.
Construindo o Aplicativo
Criaremos uma nova pasta com o nome nodejs-debugging e, em seguida, inseriremos o comando npm init -y dentro dessa pasta para criar um arquivo package.json. Em seguida, instalaremos os pacotes Express, nodemon, axios e cors executando npm i express axis cors nodemon. ExpressJS é uma estrutura NodeJS minimalista, axios nos ajudará a buscar os dados corretamente, cors garantirá que não encontraremos erros de cors e nodemon observará o servidor enquanto fazemos alterações nele.
Considerando que o sistema operacional que estamos usando é o Linux, também inseriremos os seguintes comandos para criar algumas pastas e um index.js: mkdir controladores rotas de dados e touch index.js. Antes de iniciar nosso código, iremos para o arquivo package.json e alterá-lo-emos como tal:
{
"name": "testing-tips-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js",
"dev": "nodemon index.js"
},
"keywords": ,
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^1.4.0",
"cors": "^2.8.5",
"express": "^4.18.2"
}
}
Como você pode ver, nos scripts temos os comandos start e dev que executam o processo do nó e o nodemon respectivamente. Quando estiver no modo de desenvolvimento, queremos usar o nodemon para nosso próprio bem. Agora, escreveremos um servidor expresso básico no arquivo index.js.
const express = require("express");
const app = express ;
const cors = require("cors");
const routes = require("./routes/posts.js");
const port = process.env.PORT 5000;
app.use(cors );
app.get(" (req, res) => {
res.send("Hello World!");
});
const value = 5 - 3;
app.use("/posts", routes);
app.listen(port, => {
console.log(`Example app listening at
});
Você verá que incluímos algumas linhas extras como rotas, postagens e um valor. Nosso servidor não funcionará agora se executarmos npm run dev porque ainda não temos essas rotas. A razão pela qual estamos fazendo isso dessa maneira é modularizar nosso código tanto quanto possível para que, quando quisermos saber o que está onde e por quê, encontraremos uma estrutura de pastas gerenciada adequadamente em vez de um grande arquivo index.js.
Escrevendo os controladores
Agora, em nosso diretório controllers, criaremos um arquivo controllers.js e adicionaremos o seguinte trecho dentro dele:
const axios = require("axios");
const fs = require("fs");
const path = require("path");
const crypto = require("crypto");
const getPosts = async (req, res) => {
try {
const response = await axios.get(
"
{ params: { _limit: 15 } }
);
const dataFolder = path.join(__dirname, "../data");
const dataFile = "posts.json";
if (!fs.existsSync(dataFolder)) {
fs.mkdirSync(dataFolder);
}
const postData = response.data.map((post) => {
const rating = crypto.randomInt(1, 11); // Generate a random integer between 1 and 10, inclusive
return {
...post,
rating,
};
});
fs.writeFileSync(path.join(dataFolder, dataFile), JSON.stringify(postData));
res.status(200).json(postData);
} catch (error) {
res.status(404).json({
message: error.message,
});
}
};
module.exports = {
getPosts,
};
Vamos repassar o que está acontecendo neste código.
Começamos importando os módulos necessários, como axios para busca, fs para sistema de arquivos, caminho para caminho e criptografia para criar um número aleatório. Então, com nossa função assíncrona getPosts, estamos enviando uma solicitação get para “https://jsonplaceholder.typicode.com/posts” e limitando a quantidade de objetos que receberemos em 15. Este jsonplaceholder é uma API fictícia bastante útil no desenvolvimento.
Em seguida, especificamos onde criaremos um arquivo posts.json (pasta de dados) e confirmamos que criaremos a pasta caso ela ainda não exista para que não encontremos erro devido à sua ausência. Então, para cada item que temos, estamos criando um número aleatório entre 1 e 10 inclusive. Posteriormente, usando o operador spread, estamos adicionando este novo par chave/valor de classificação aleatória aos dados que já temos. Para encerrar, amarramos tudo e tratamos o erro por meio da instrução catch.
Por último, exportamos a função getPosts para que possamos utilizá-la nas rotas.
Se tudo correr bem, devemos ter um arquivo data/posts.json com 15 itens dentro dele, que se parece com:
{
"userId": 1,
"id": 10,
"title": "optio molestias id quia eum",
"body": "quo et expedita modi cum officia vel magni\ndoloribus qui repudiandae\nvero nisi sit\nquos veniam quod sed accusamus veritatis error",
"rating": 6
},
{
"userId": 2,
"id": 11,
"title": "et ea vero quia laudantium autem",
"body": "delectus reiciendis molestiae occaecati non minima eveniet qui voluptatibus\naccusamus in eum beatae sit\nvel qui neque voluptates ut commodi qui incidunt\nut animi commodi",
"rating": 5
},
{
"userId": 2,
"id": 12,
"title": "in quibusdam tempore odit est dolorem",
"body": "itaque id aut magnam\npraesentium quia et ea odit et ea voluptas et\nsapiente quia nihil amet occaecati quia id voluptatem\nincidunt ea est distinctio odio",
"rating": 4
},
Aqui, os campos userId, id, title e body são retornados da API e adicionamos o campo de classificação com um número aleatório.
Agora que escrevemos nossos controladores, é hora de escrever as rotas para ele, para que possamos importá-lo em index.js e chamá-lo via curl ou uma ferramenta como o Postman.
Escrevendo as rotas
Vamos para o diretório de rotas e criar um arquivo posts.js e colar o seguinte trecho dentro dele:
const express = require("express");
const router = express.Router ;
const { getPosts } = require("../controllers/controllers.js");
router.get(" getPosts);
module.exports = router;
Aqui, ao importar o Express e usar seu roteador, estamos criando uma rota base para a função getPosts que obtemos do controllers.js. Também exportamos o roteador. Agora, nosso arquivo index.js faz sentido. Se enviarmos uma solicitação get para o arquivo data/posts.json será criado conforme especificado.
Depuração via Terminal e Watchers
Agora que temos um projeto funcional pronto, podemos começar a brincar com a funcionalidade de depuração do NodeJs. A primeira opção que temos é executar node inspecionar index.js (ou o arquivo que queremos inspecionar), e devemos receber esta mensagem no terminal:
< Debugger listening on ws://127.0.0.1:9229/0d56efaa-fd7f-4993-be76-0437122ae1cf
< For help, see:
<
connecting to 127.0.0.1:9229 ... ok
< Debugger attached.
<
Break on start in index.js:1
> 1 const express = require("express");
2 const app = express ;
3 const cors = require("cors");
debug>
Agora, estamos no domínio da depuração. Podemos inserir certas palavras-chave para realizar ações.
- Pressionar c ou cont continuará a execução do código até o próximo ponto de interrupção ou até o final.
- Pressionar n ou próximo irá para a próxima linha.
- Pressionar s ou step entrará em uma função.
- Pressionar o sairá de uma função
- A pausa de escrita pausará o código em execução.
Se pressionássemos “n” algumas vezes, e depois de vermos a constante de valor escrever watch('value') e pressionarmos n mais uma vez, veríamos algo assim no terminal:
18 app.listen(port, => {
debug> watch('value')
debug> n
break in index.js:18
Watchers:
0: value = 2
16 app.use("/posts", routes);
Como você pode ver, como especificamos que queremos observar a constante de valor, o depurador JS nos mostra o resultado da operação, e esse é o número 2. Essa abordagem é semelhante à adição de instruções console.log em algum sentido mas principalmente útil em um escopo muito pequeno. Imagine se tivéssemos que pressionar n centenas de vezes para entrar em uma fila – isso não seria muito produtivo. Para isso, temos outra opção.
Depuração usando a palavra-chave debugger
Aqui, alteramos o arquivo index.js adicionando a palavra-chave debugger após a constante de valor:
const express = require("express");
const app = express ;
const cors = require("cors");
const routes = require("./routes/posts.js");
const port = process.env.PORT 5000;
app.use(cors );
app.get(" (req, res) => {
res.send("Hello World!");
});
const value = 5 - 3;
//added debugger keyword after the value constant
debugger;
app.use("/posts", routes);
app.listen(port, => {
console.log(`Example app listening at
});
Quando executarmos novamente node inspecionar index.js, agora, em vez de pressionar manualmente a tecla n repetidamente, podemos pressionar c, e o depurador irá diretamente para onde a palavra-chave do depurador foi declarada. Podemos, portanto, adicionar nossos observadores como desejarmos, como antes. Aqui está um trecho do fluxo de trabalho completo descrito:
sirius@sirius-20t8001ttx ~/c/a/testing-tips-nodejs (SIGINT)> node inspect index.js
< Debugger listening on ws://127.0.0.1:9229/03f908f6-b6ce-4337-87b4-ed7c6eb2a027
<
< For help, see: https://nodejs.org/en/docs/inspector
<
ok
< Debugger attached.
<
Break on start in index.js:1
> 1 const express = require("express");
2 const app = express ;
3 const cors = require("cors");
//pressing c here
debug> c
//jumps directly to line 15 where the debugger keyword has been declared
break in index.js:15
13
14 const value = 5 - 3;
>15 debugger;
16
17 app.use("/posts", routes);
//adding watcher to value constant
debug> watch('value')
//going to the next line
debug> n
break in index.js:17
//we can see our watchers
Watchers:
0: value = 2
15 debugger;
16
>17 app.use("/posts", routes);
18
19 app.listen(port, => {
debug>
Chrome DevTools: o depurador Node JS
Agora vamos mudar um pouco nossa estratégia e usar outras ferramentas de depuração. Imagine que cometemos um erro em nossos controladores. Em vez de escrever const rating = crypto.randomInt(1, 11); , escrevemos const rating = crypto.randomInt(-11, 11); .
Agora, como escrevemos -11 em vez de 1, as classificações também terão números negativos, e não queremos isso. Executamos nosso aplicativo, enviamos a solicitação get e percebemos que as classificações incluem números negativos. Embora este seja um caso bastante óbvio, imagine que estamos lidando com uma função enorme que chama outras funções que chamam outras funções, e precisamos descobrir onde surge o problema. Se estivermos usando navegadores Chrome ou baseados em Chromium, temos o Chrome Dev Tools à nossa disposição para verificar o estado do aplicativo em qualquer ponto de depuração de uma forma que seja mais fácil de acompanhar visualmente. Para começar, vamos parar nosso servidor e alterar a função postData em ontrollers.js assim:
const postData = response.data.map((post) => {
const rating = crypto.randomInt(-11, 11); // Generate a random integer between 1 and 10, inclusive
console.log(rating);
debugger;
return {
...post,
rating,
};
});
Em seguida, executamos novamente nosso aplicativo com um comando ligeiramente diferente => node –inspect index.js. Agora, com as linhas incluídas antes da palavra-chave inspecionar, temos acesso ao servidor através do nosso navegador. Vamos para o seguinte link => chrome://inspect/#devices . Aqui, devemos ver algo assim:
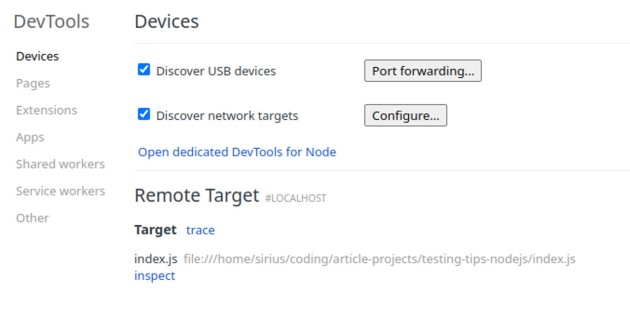
Aqui, clicaremos em “Abrir DevTools dedicados para Node”, que abrirá algo assim:
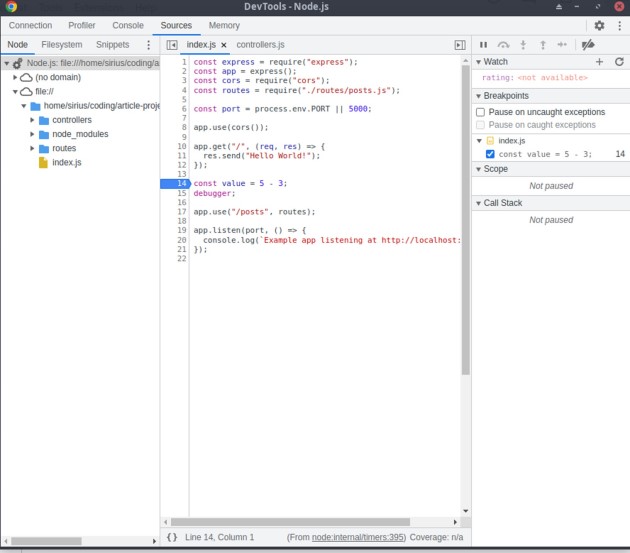
Há muitas coisas acontecendo aqui. Como você pode ver, à esquerda podemos alterar os diretórios e arquivos como quisermos e inspecionar o código. À direita podemos definir watchers, as palavras-chave que o depurador irá procurar. Entramos ali “rating”, porque queremos ver o valor das classificações. Se não tivéssemos incluído a palavra-chave debugger no arquivo controllers.js também, não seríamos capazes de ver o valor das classificações. Agora, se abrirmos o Postman e reenviarmos uma solicitação get para /posts, deveremos receber uma tela como esta:
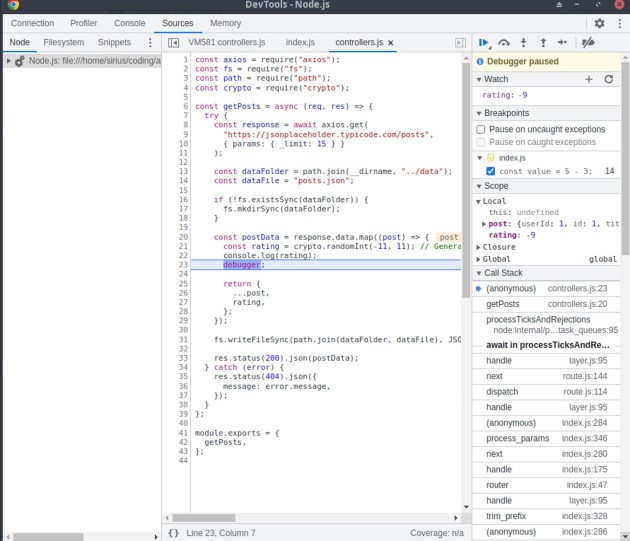
Agora você vê que o valor da classificação é -9. Podemos inferir que fizemos algo errado em nosso código que causou esse comportamento e verificar se a constante de classificação aceita valores entre -11 e 11. Agora, se clicarmos em F8 para retomar a execução, veríamos um valor diferente como então:
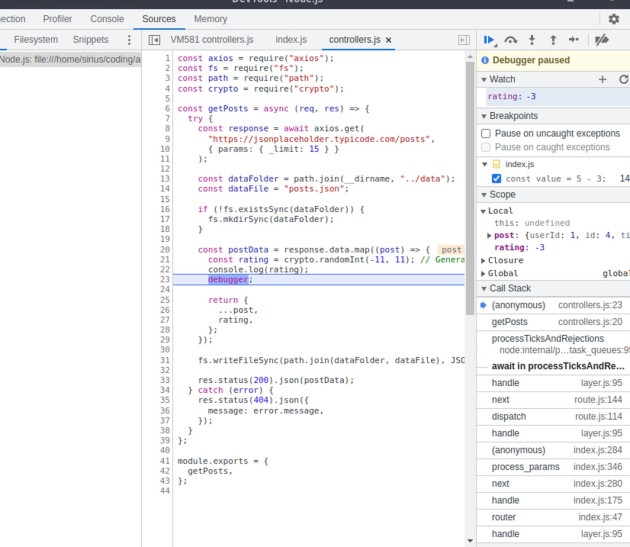
Além disso, se verificarmos o que está acontecendo com o Postman, veremos que a execução ainda está em andamento porque o aplicativo para na palavra-chave debugger. Agora também podemos fazer a mesma coisa diretamente no VS Code.
Depuração com código do Visual Studio
Agora é hora de depurar o código diretamente no VS Code. A primeira coisa que precisamos fazer é fechar nosso servidor de inspeção e abrir o VS Code. Lá, no lado esquerdo, deve haver uma seção Executar e Depurar. Se clicarmos nele, será exibida uma tela como esta:
Aqui, escolheremos “criar um arquivo launch.json” e então, na linha de comando, se for aberto, escolheremos “NodeJs”, e ele criará um arquivo launch.json para nós que se parece com isto:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit:
"version": "0.2.0",
"configurations": (
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"skipFiles": (
"<node_internals>/**"
),
"program": "${workspaceFolder}/index.js"
}
)
}
Agora, se clicarmos em iniciar no canto superior esquerdo, ou clicarmos em F5 desta vez, o próprio servidor de inspeção será iniciado. Se enviarmos uma solicitação get via Postman, ela nos enviará para a palavra-chave debugger no arquivo controllers.js:
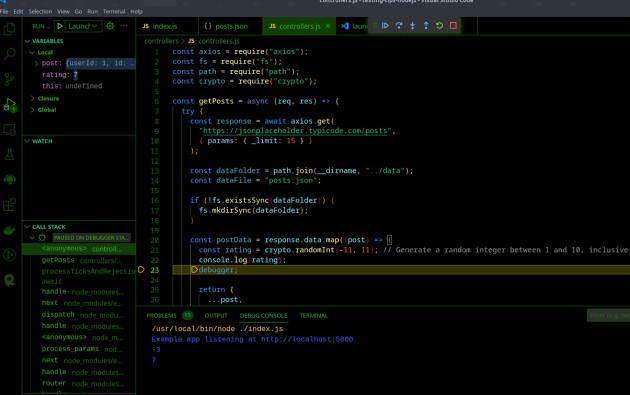
Aqui também, assim como o Chrome Dev Tools, cada atualização resultaria em um valor de classificação diferente. Usando esta ferramenta e técnica, podemos novamente observar e ver que há algo errado com as classificações e, então, devemos verificar o que está causando o problema.
Conclusão
Ao longo deste tutorial, exploramos várias estratégias para depuração de aplicativos NodeJS, destacando a importância dos métodos além das simples instruções console.log. Como forma de garantir um processo de desenvolvimento mais tranquilo, pode ser vantajoso terceirizar o desenvolvimento do NodeJS. Ao fazer isso, você poderá aproveitar as habilidades e a experiência de especialistas na área, melhorando assim a qualidade geral e a eficiência do seu projeto.
Se você gostou deste artigo, confira nossos outros guias abaixo;
- Alterar versão do nó: um guia passo a passo
- Cache Node JS: aumentando o desempenho e a eficiência
- Desbloqueie o poder dos microsserviços Node.JS
- Desbloqueando o poder do Websocket Nodejs
- Melhores editores de texto e IDE Node JS para desenvolvimento de aplicativos
Perguntas frequentes
Quais são algumas das práticas recomendadas a serem seguidas durante a depuração em Node.js?
Durante uma sessão de depuração no Node.js, algumas das práticas recomendadas a seguir incluem obter uma compreensão abrangente do depurador integrado e usá-lo de maneira eficaz. Também é benéfico incorporar ferramentas externas, como Chrome DevTools e VS Code, em sua configuração de depuração. Em vez de depender muito de “console.log”, considere substituí-lo por ferramentas de registro e depuração mais robustas, sempre que possível. Também é crucial se familiarizar com as opções ‘inspect’ e ‘inspect-brk’ disponíveis no Node.js, que permitem interromper a execução do código javascript e percorrê-lo metodicamente. A incorporação de linters em sua configuração de depuração também é recomendada, pois eles ajudam a identificar erros comuns de codificação desde o início.
Por último, a prática de escrever testes unitários continua inestimável; não apenas ajuda a identificar bugs, mas também funciona preventivamente para evitar possíveis problemas futuros.
Como posso utilizar ferramentas de depuração integradas no Node.js para aprimorar meu processo de depuração?
Node.js está equipado com uma ferramenta de depuração integrada robusta que pode amplificar notavelmente seu processo de depuração. Para utilizar esta ferramenta, inicie o depurador executando seu aplicativo com as opções de linha de comando 'inspect' ou 'inspect-brk', seguidas pelo caminho para seu script. Por exemplo, usar 'node inspecionar aplicativo' colocaria seu aplicativo no modo de depuração. A opção 'inspect-brk', por outro lado, permite que seu script comece, mas pausa a execução até que um cliente de depuração seja conectado, dando a você a capacidade de depurar o processo de inicialização do seu script.
Depois que o cliente de depuração estiver operacional, ele permitirá que você percorra meticulosamente seu código, investigue variáveis e avalie expressões. Ao incorporar a palavra-chave 'debugger' em seu código, você pode definir pontos de interrupção que pausam a execução de seu script, permitindo examinar detalhadamente o estado do programa. Isso pode ser monitorado convenientemente no console de depuração. Se você preferir uma interface gráfica para uma experiência mais intuitiva, tanto o depurador Chrome DevTools quanto o VS Code fornecem soluções viáveis. Seu painel de depuração pode se conectar à sessão de depuração do Node, garantindo um processo de depuração amigável que representa visualmente o estado do seu código e o fluxo de execução.
Você pode dar um exemplo de uma técnica avançada de depuração do Node.js e como usá-la de maneira eficaz?
Uma técnica avançada de depuração do Node.js envolve o uso do processo de depuração 'post-mortem'. Neste método, um 'core dump', ou um instantâneo detalhado do estado do aplicativo, é criado quando o aplicativo encontra uma falha ou outro evento crítico. A análise desses core dumps, que podem ser alcançados usando ferramentas como ‘llnode’ e ‘mdb_v8’, oferece insights profundos sobre o que levou ao problema. A geração de um core dump pode ser iniciada a partir do prompt de depuração usando opções integradas do Node.js ou módulos externos como 'node-report' ao executar seu aplicativo, por exemplo, 'node app'.
Quando seu aplicativo trava ou é acionado manualmente, o 'node-report' irá gerar um arquivo de resumo de diagnóstico que é fácil de compreender. Este arquivo apresenta informações vitais sobre a pilha JavaScript, pilha nativa, estatísticas de heap, informações do sistema e uso de recursos, que podem ser indispensáveis ao depurar problemas difíceis de reproduzir.
Embora esta técnica avançada exija um conhecimento profundo da linguagem e do tempo de execução, seu uso eficaz pode expor a causa subjacente de bugs complicados, especialmente aqueles relacionados ao desempenho e falhas do sistema.
Fonte: BairesDev







