Aumente o desempenho do seu Node JS com técnicas de cache! Aprenda como implementar o cache em seus projetos e melhorar a velocidade do seu aplicativo.

Você está cansado de consultas de banco de dados lentas e que consomem muitos recursos em seu aplicativo Node.js? Você pode se livrar desses problemas e melhorar o desempenho armazenando em cache o aplicativo node js. O cache é uma técnica importante no desenvolvimento de software que tem sido utilizada para melhorar o desempenho de aplicações, levando a um processo eficiente de recuperação de dados, fornecendo um mecanismo intermediário de armazenamento. Envolve o armazenamento de dados e objetos acessados com frequência em uma área de armazenamento temporário, para que possam obter rapidamente os dados recuperados quando necessário.
Este artigo abordará os fundamentos do cache, uma visão geral do servidor Redis, a implementação do cache no Redis e as diferentes soluções disponíveis no mercado. Ao final deste artigo, você entenderá melhor os cenários em que o cache é útil, o que armazenar em cache e as técnicas apropriadas para implementar o cache em seus aplicativos Node.js com base em seu caso de uso específico.
O que é Node.js?

Node.js é um ambiente de tempo de execução JavaScript do lado do servidor de código aberto construído no mecanismo JavaScript V8 do Google Chrome, que permite aos desenvolvedores escrever código do lado do servidor usando a sintaxe JavaScript em vez de outra linguagem como Java ou Python. Facilita a vida dos desenvolvedores front-end familiarizados com a programação do lado do cliente, permitindo-lhes trabalhar no código back-end e vice-versa, permitindo que os desenvolvedores back-end que se sentem mais confortáveis trabalhando em tarefas do servidor, como bancos de dados ou APIs, acessem prontamente as mesmas linguagens e bibliotecas disponível para navegadores da Web, o que significa menos tempo gasto aprendendo novas tecnologias apenas porque você alternou entre codificação do lado do cliente/servidor.
Isso torna o NodeJS altamente popular entre as estruturas modernas de aplicativos da web, pois é introdução em 2009 por Ryan Dahl devido em grande parte ao fato de que ele utiliza operações de E/S assíncronas sem bloqueio, que permitem aos programas escritos em Node.js características de utilização de recursos muito melhores do que os métodos síncronos tradicionais, onde todas as solicitações devem esperar até que uma solicitação seja concluída.
Por que armazenar dados em cache em primeiro lugar?

Armazenar dados em cache é uma prática comum para um processo eficiente de recuperação de dados. Os dados armazenados em cache reduzem a latência ao acessar grandes conjuntos de dados. Ao manter os itens solicitados recentemente à mão, os tempos de recuperação são mais rápidos do que se eles tivessem que ser recuperados de sua fonte sempre que uma solicitação fosse feita. Além disso, isso permite um uso mais eficiente dos recursos, uma vez que diversas solicitações de dados solicitados semelhantes podem ser tratadas com apenas uma consulta, em vez de fazer solicitações separadas a cada vez.
Por exemplo, se um aplicativo precisar de informações de previsão do tempo a cada hora, armazenar esses dados em cache economizaria tempo porque novas previsões não precisariam ser baixadas repetidamente ao longo do dia. Em vez disso, eles poderiam recuperar dados no início de cada hora usando dados armazenados em cache na memória.
Outro benefício do armazenamento em cache é a escalabilidade aprimorada, uma vez que menos chamadas remotas precisam ser feitas, o que reduz a carga do servidor e amplia a capacidade, permitindo o acesso de mais usuários sem diminuir os tempos de resposta devido à pressão excessiva sobre os recursos do sistema, pois leva ao cache dos dados consultados com frequência. Ele também garante que, quando ocorrerem picos de tráfego devido ao aumento da demanda, ainda haverá níveis suficientes de serviço disponíveis, pois o cache armazena consultas de alta frequência localmente, evitando assim lentidão associada a interrupções de fontes remotas, como APIs ou bancos de dados que podem não ter sido projetado para esperar que grandes números de chamadas simultâneas sejam feitas de uma só vez.
O cache também aumenta a segurança, pois evita que informações confidenciais do usuário, como senhas ou detalhes de cartão de crédito, sejam expostas em redes abertas, onde partes não autorizadas podem interceptá-las antes de atingirem o alvo pretendido – outra camada adicional de proteção que pode impedir ataques maliciosos em sistemas que hospedam registros confidenciais de clientes. certificando-se de que apenas aqueles autorizados a acessar o que está dentro
Os dados armazenados em cache podem proporcionar economia de custos, uma vez que inúmeras operações de armazenamento e busca de dados não precisam acontecer, resultando em menor uso de recursos e mantendo o mesmo nível de qualidade de serviço esperado pelos clientes que esperam experiências rápidas e responsivas, independentemente de quantas pessoas estão usando um determinado produto ou serviço.
Tipos de cache
Existem vários tipos de cache que podem ser usados em vários contextos, incluindo cache do lado do cliente, cache do lado do servidor e redes de distribuição de conteúdo (CDNs). Cada tipo de cache tem benefícios e é adequado para diferentes casos de uso, por isso é importante compreender suas diferenças para escolher a estratégia de cache certa para suas necessidades específicas.
| Tipo de cache | Definição | Exemplos |
| Cache do lado do cliente | Cache de páginas da web e recursos no computador do usuário. | Cache de imagens, CSS e JavaScript do navegador |
| Cache do lado do servidor | Armazenar componentes de sites ou aplicativos em um servidor externo. | Memcached, Redis e LevelDB |
| Redes de distribuição de conteúdo (CDNs) | Grandes sistemas distribuídos que fornecem conteúdo estático em cache. | Cloudflare, Akamai e Amazon CloudFront |
A tabela descreve as vantagens e desvantagens de cada tipo de cache em termos de fatores como capacidade, disponibilidade, escalabilidade e complexidade de implementação. Em última análise, a escolha da estratégia de cache dependerá das necessidades e requisitos específicos de um determinado projeto ou aplicação.
Quando usar o Redis para armazenamento em cache?

O cache Redis é um tipo de armazenamento de banco de dados que fornece acesso de alta velocidade aos dados armazenados na memória. Os caches Redis são uma excelente escolha para aplicações onde grandes dados devem ser recuperados e armazenados rapidamente. Isso os torna particularmente adequados para aplicativos baseados na Web, como aqueles usados por sites de comércio eletrônico ou sistemas de gerenciamento de conteúdo (CMS).
Ao decidir usar o cache Redis, é importante considerar o tamanho e a complexidade do seu aplicativo. Por exemplo, se você tiver um site pequeno com tráfego mínimo, pode não haver necessidade de cache Redis, pois seus benefícios podem não compensar o custo envolvido na configuração do sistema. No entanto, usar o Redis pode fazer sentido se você tiver um site maior com visitantes regulares ou clientes que exigem tempos de resposta rápidos do seu servidor.
Outro fator ao considerar o uso do cache Redis é a frequência com que os dados precisam ser acessados e atualizados no lado do servidor, tornando as operações de acesso aos dados mais rápidas. Se os dados mudarem com frequência, o uso do Redis poderá fornecer melhor desempenho em comparação com outros métodos, como banco de dados baseado em disco, devido à sua capacidade de lidar com várias solicitações simultaneamente, sem diminuir significativamente a velocidade. Ele também permite que os desenvolvedores tenham mais controle sobre como as atualizações são tratadas para garantir que as novas informações sejam distribuídas entre todos os clientes conectados de forma rápida e confiável, em vez de esperar até que cada solicitação seja processada antes de atualizá-la em todos os servidores simultaneamente, o que pode levar mais tempo dependendo da latência da rede. etc.
Além disso, outro benefício importante oferecido pelo uso do cache Redis é a escalabilidade; isso significa que, caso seu site experimente aumentos repentinos na base de usuários ou nos níveis de atividade, a expansão da capacidade por meio de nós adicionais se tornará muito mais simples do que ter uma configuração de banco de dados tradicional feita manualmente, o que consome tempo e recursos de outros aspectos, como a criação de novos recursos/funcionalidades para usuários, etc
Como as versões em cache dos objetos permanecem armazenadas na RAM, os tempos de carregamento da página geralmente diminuirão junto com o aumento da taxa de transferência devido novamente à redução da latência associada à recuperação de informações diretamente das unidades de disco versus locais de memória onde tudo acontece quase instantaneamente, levando assim a melhorias adicionais na capacidade de resposta geral. visto pelos usuários finais, tornando suas interações mais suaves e rápidas, o que ajuda a criar melhores experiências em geral, independentemente do dispositivo através do qual eles estão visualizando as coisas – telefones celulares, tablets, laptops, desktops, etc.
Implementar cache no Node JS

Digamos que temos um site de comércio eletrônico exibindo uma lista de usuários. Cada vez que o URL é acessado, o aplicativo consulta o banco de dados para buscar os usuários mais recentes, o que pode ser lento e consumir muitos recursos. Podemos usar o cache Redis para armazenar os resultados da consulta ao banco de dados e servi-los diretamente do cache para solicitações subsequentes.
Veja como você pode implementar o cache Redis em um aplicativo Node.js:
Pré-requisitos
- Redis: Redis é um armazenamento de estrutura de dados na memória que pode ser usado como banco de dados, cache e intermediário de mensagens.
- Node.js: Node.js é um ambiente de execução JavaScript de plataforma cruzada e código aberto que permite aos desenvolvedores criar aplicativos do lado do servidor usando JavaScript.
- Cliente Redis para Node.js: para usar Redis em Node.js, você deve instalar uma biblioteca cliente Redis como “redis” por meio de npm.
- Conhecimento básico de comandos Redis: Antes de executar o cache com Redis, você precisa ter um compreensão básica dos comandos Redis como SET, GET e EXPIRE, que são usados para armazenar, recuperar e expirar dados, respectivamente.
Etapa 1: instalar o servidor Redis
Você pode baixar o instalador usando o site oficial do Redis. Siga as instruções do seu sistema operacional para instalar o Redis.
Alternativamente, você pode usar um gerenciador de pacotes para instalar o Redis. Por exemplo, no Ubuntu ou Debian Linux, você pode usar o seguinte comando:
sudo apt-get install redis-server
No macOS, você pode usar o Homebrew para instalar o Redis:
brew install redis
No Linux, após instalar o Redis, você pode iniciar o servidor Redis executando o seguinte comando em um terminal:
redis-server
No macOS, você pode iniciar o servidor Redis executando o seguinte comando em um terminal:
redis-server /usr/local/etc/redis.conf
No Windows, após a instalação do site, você pode iniciar o servidor Redis executando o seguinte comando em uma janela do Prompt de Comando:
redis-server.exe
Isso inicia o Redis com configurações padrão.
Etapa 2: crie um novo projeto Node.js.
- Crie um novo diretório para o seu projeto e navegue até ele no seu terminal.
- Execute o seguinte comando para criar um novo arquivo package.json:
npm init -y
Seu arquivo package.json deve ser parecido com isto:
{
"name": "redis-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": ,
"author": "",
"license": "ISC",
}
Etapa 3: instale as dependências necessárias
Em seguida, você precisará instalar os seguintes pacotes:
- express: uma estrutura de servidor web para Node.js.
- node-redis: um cliente Redis que permite armazenar e acessar dados no Redis.
Instale a estrutura web Express e o cliente Redis para Node.js usando o seguinte comando:
npm install express redis axios
Seu arquivo package.json deve ficar parecido com isto após a instalação dos pacotes necessários:
{
"name": "redis-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": ,
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^1.3.4",
"express": "^4.18.2",
"redis": "^4.6.5"
}
}
Etapa 4: configurar um cliente Redis em seu aplicativo Node.js
Em seu aplicativo Node.js, crie um novo arquivo chamado server.js e adicione o seguinte código a ele:
const express = require('express');
const redis = require('redis');
const { createClient } = require('redis');
const app = express ;
const port = process.env.PORT 3000;
No trecho de código acima, você importa os módulos necessários para configurar um servidor Express e um cliente Redis em Node.js.
Em seguida, crie uma instância do aplicativo Express usando const app = express e defina a variável port como o valor da variável de ambiente definida no arquivo .env ou 3000 se não estiver definido.
Agora você está pronto para começar a construir seu sistema de cache usando Redis e Express.
Este código configura um cliente Redis usando a biblioteca Node.js Redis e se conecta a um servidor Redis.
Etapa 5: crie um cliente Redis e conecte-se a um servidor Redis
Agora adicione o seguinte código ao arquivo server.js:
let redisClient;
(async => {
redisClient = createClient ;
redisClient.on("error", (error) => console.error(`Error : ${error}`));
await redisClient.connect ;
}) ;
A primeira linha declara uma variável chamada redisClient, que armazenará o objeto cliente Redis.
O código então define uma expressão de função invocada imediatamente (IIFE) usando a sintaxe async/await, que faz o seguinte:
- Cria um cliente Redis usando a função createClient . Esta função é fornecida pela biblioteca Node.js Redis e cria um novo objeto cliente Redis que pode ser usado para interagir com um servidor Redis.
- Registra um manipulador de erros no objeto cliente Redis, que registra quaisquer erros no console.
- Chama o método connect no objeto cliente Redis usando await, que estabelece uma conexão com o servidor Redis. Este método retorna uma promessa, por isso precisa ser aguardada.
Etapa 6: buscar dados de uma API externa
Agora adicione a seguinte função para buscar dados da API.
async function fetchApiData {
const apiResponse = await axios.get(
`
);
console.log("Request sent to the API");
return apiResponse.data;
}
Etapa 7: cache de solicitações do servidor JS do nó
Adicione a seguinte função getUsersData, que primeiro extrai o parâmetro users do objeto de solicitação usando req.params.users. Em seguida, ele declara duas variáveis results e isCached, inicializando a última como false, pois inicialmente não haveria cache.
async function getUsersData(req, res) {
const users = req.params.users;
let results;
let isCached = false;
try {
const cacheResults = await redisClient.get(users);
if (cacheResults) {
isCached = true;
results = JSON.parse(cacheResults);
} else {
results = await fetchApiData ;
if (results.length === 0) {
throw "API returned an empty array";
}
await redisClient.set(users, JSON.stringify(results));
}
res.send({
fromCache: isCached,
data: results,
});
} catch (error) {
console.error(error);
res.status(404).send("Data unavailable");
}
}
Em seguida, a função tenta recuperar resultados armazenados em cache de um banco de dados Redis usando a chamada de função redisClient.get(users). Se existirem resultados armazenados em cache, a variável isCached será definida como true e os resultados armazenados em cache serão analisados a partir de uma string JSON usando JSON.parse(cacheResults).
Se nenhum resultado armazenado em cache for encontrado, a função chama outra função assíncrona fetchApiData para obter resultados. Se fetchApiData retornar um array vazio, uma exceção será lançada com a mensagem “API retornou um array vazio”.
Se fetchApiData retornar resultados não vazios, a função armazenará os resultados como uma string JSON no cache Redis usando redisClient.set(users, JSON.stringify(results)).
Por fim, a função envia uma resposta ao cliente com um objeto contendo a variável isCached e os dados dos resultados, usando res.send({ fromCache: isCached, data: results }). Se uma exceção for detectada durante a execução do bloco try, a função registra um erro no console e envia uma resposta 404 com a mensagem “Dados indisponíveis” usando res.status(404).send(“Dados indisponíveis”).
Etapa 8: configurar rotas de aplicativos
Adicione as seguintes rotas ao aplicativo.
app.get("/users/:users", getUsersData);
app.listen(port, => {
console.log(`App listening on port ${port}`);
});
O arquivo server.js consolidado deve ser parecido com isto.
const express = require('express');
const redis = require('redis');
const { createClient } = require('redis');
const app = express ;
const port = process.env.PORT 3000;
let redisClient;
(async => {
redisClient = createClient ;
redisClient.on("error", (error) => console.error(`Error : ${error}`));
await redisClient.connect ;
}) ;
async function fetchApiData {
const apiResponse = await axios.get(
`
);
console.log("Request sent to the API");
return apiResponse.data;
}
async function getUsersData(req, res) {
const users = req.params.users;
let results;
let isCached = false;
try {
const cacheResults = await redisClient.get(users);
if (cacheResults) {
isCached = true;
results = JSON.parse(cacheResults);
} else {
results = await fetchApiData ;
if (results.length === 0) {
throw "API returned an empty array";
}
await redisClient.set(users, JSON.stringify(results));
}
res.send({
fromCache: isCached,
data: results,
});
} catch (error) {
console.error(error);
res.status(404).send("Data unavailable");
}
}
app.get("/users/:users", getUsersData);
app.listen(port, => {
console.log(`App listening on port ${port}`);
});
Etapa 9: inicie o servidor e teste o cache do Redis
Inicie o servidor executando o seguinte comando em seu terminal:
node server.js
Etapa 10: Acessando os Dados Recuperados
Você terá que visitar para ver os dados solicitados. O servidor irá buscar dados.

Recarregue a página algumas vezes. Agora você pode ver que os dados solicitados mostram que fromCache são verdadeiros. Isso significa que você vê os dados do cache.
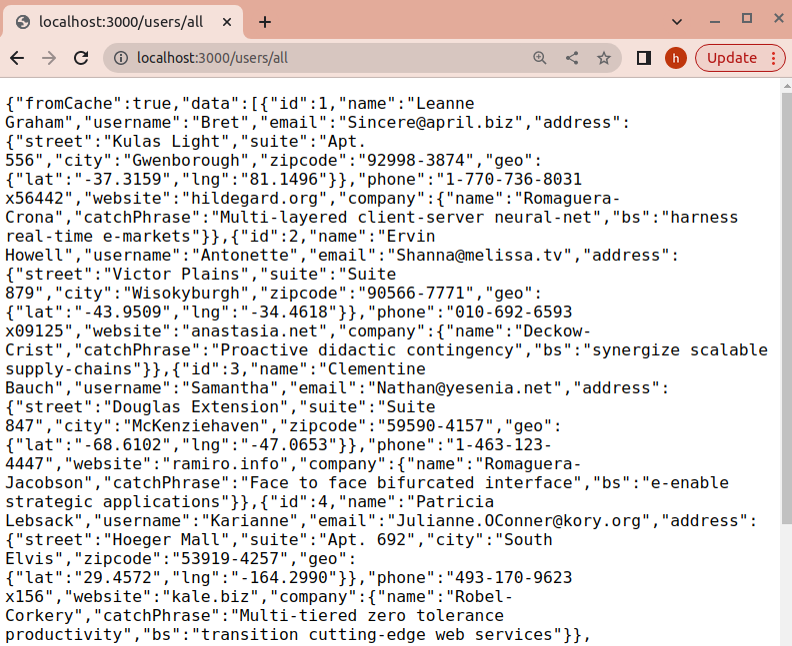
É isso! Com essas etapas, agora você deve ter uma implementação básica de cache usando Redis com Node.js em seu aplicativo de comércio eletrônico.
Alternativas
Redis é um armazenamento de estrutura de dados na memória popular e poderoso. Tornou-se cada vez mais popular como alternativa aos sistemas de banco de dados tradicionais devido à sua escalabilidade, alto desempenho e flexibilidade. O Redis nem sempre pode ser a melhor solução para cada aplicativo ou caso de uso específico. Existem várias alternativas ao Redis em Node.js, cada uma com recursos, vantagens e limitações. Aqui estão algumas das alternativas mais populares ao Redis:
Memcached
Memcached é um sistema de cache de objetos de memória distribuída de alto desempenho. Ele foi projetado para armazenar em cache dados acessados com frequência na memória para reduzir o tempo que um aplicativo deve buscar dados de um banco de dados ou outra fonte. Memcached é frequentemente usado para aplicativos da web em grande escala que exigem acesso aos mesmos dados em alta velocidade.
Uma das vantagens do Memcached sobre o Redis é a sua simplicidade. É fácil de usar e ocupa pouco espaço de memória, o que o torna ideal para projetos menores ou aplicativos com recursos limitados. No entanto, o Memcached não oferece alguns dos recursos mais avançados do Redis, como persistência ou tipos de dados avançados.
MongoDB
MongoDB é um banco de dados NoSQL popular que pode ser usado como alternativa ao Redis. O MongoDB foi projetado para armazenar e gerenciar grandes quantidades de dados não estruturados, tornando-o uma boa opção para aplicações que exigem flexibilidade de armazenamento de dados.
Uma das vantagens do MongoDB sobre o Redis é a sua escalabilidade. O MongoDB pode lidar com grandes quantidades de dados e foi projetado para escalar horizontalmente em vários servidores. Ele também oferece recursos de consulta mais avançados que o Redis, tornando-o uma escolha melhor para aplicativos complexos de recuperação de dados.
Apache Cassandra
Apache Cassandra é um banco de dados NoSQL altamente escalonável que pode ser usado como alternativa ao Redis. Cassandra foi projetado para lidar com grandes quantidades de dados em vários servidores e pode fornecer alta disponibilidade e tolerância a falhas.
Uma das vantagens do Cassandra sobre o Redis é a sua escalabilidade. Cassandra pode lidar com grandes quantidades de dados e foi projetado para escalar horizontalmente em vários servidores. Ele também oferece recursos de consulta mais avançados que o Redis, tornando-o uma escolha melhor para aplicativos complexos de recuperação de dados.
NívelDB
LevelDB é um armazenamento de valores-chave de código aberto que pode ser usado como uma alternativa ao Redis. LevelDB foi projetado para ser leve e rápido, tornando-o uma boa escolha para projetos menores ou aplicativos com recursos limitados.
Uma das vantagens do LevelDB sobre o Redis é a sua simplicidade. É fácil de usar e ocupa pouco espaço de memória, o que o torna ideal para projetos menores ou aplicativos com recursos limitados. No entanto, o LevelDB não oferece alguns dos recursos mais avançados do Redis, como persistência ou tipos de dados avançados.
Concluindo, a escolha de uma alternativa ao Redis em Node.js dependerá dos requisitos específicos do seu projeto, como tamanho dos dados, escalabilidade e recursos de consulta necessários. Cada alternativa possui seu próprio conjunto de recursos e limitações, sendo essencial avaliá-las com base nas necessidades específicas do seu projeto.
Conclusão
Concluindo, o cache com Redis é uma excelente forma de otimizar as operações de acesso a dados em aplicações Node.js. Com a capacidade de armazenar e recuperar dados rapidamente, o cache pode melhorar significativamente o desempenho do aplicativo e a experiência do usuário. Além disso, o Redis oferece vários recursos úteis, como replicação, clustering, transações, mensagens pub/sub e muito mais, que podem ajudar os desenvolvedores a construir arquiteturas avançadas para sistemas distribuídos.
Ele também fornece soluções de alta disponibilidade que permitem implantar seu aplicativo em vários servidores ou provedores de nuvem sem se preocupar com tempo de inatividade ou problemas de latência devido a falhas de rede ou outros problemas do sistema. Todas essas vantagens tornam o Redis uma das escolhas mais populares para armazenamento em cache em aplicativos Node.js atualmente, conforme descrito em uma descrição típica de trabalho do Node.
Se você gostou deste artigo, confira nossos outros guias abaixo;
- Alterar versão do nó: um guia passo a passo
- Cache Node JS: aumentando o desempenho e a eficiência
- Desbloqueie o poder dos microsserviços Node.JS
- Desbloqueando o poder do Websocket Nodejs
- Melhores editores de texto e IDE Node JS para desenvolvimento de aplicativos