
A visão mecânica mudou drasticamente após sua convergência com a inteligência artificial. Os sistemas tradicionais de visão computacional dependiam de funções de biblioteca predefinidas e algoritmos definidos pelo usuário para todos os tipos de tarefas de processamento de imagens. Na última década, os pesquisadores perceberam que a própria visão humana é inextricável da mente e do aprendizado humanos. Foi essa constatação que levou ao uso de redes de aprendizagem profunda em visão computacional, como Redes Neurais Convolucionais (CNN) ou outro método de aprendizagem profunda. Visão de Inteligência Artificial é o termo novo e sofisticado para visão computacional ou visão de máquina.
A visão da IA tem sido computacionalmente cara e complicada. À medida que a inteligência artificial avança e os chips semicondutores se tornam cada vez mais poderosos, é possível implementar redes de aprendizagem profunda em processadores móveis e sistemas embarcados tão simples quanto microcontroladores de 32 bits. Isso mudou os modelos de visão computacional das nuvens para dispositivos de ponta, onde a visão computacional pode ser usada para aplicativos incorporados e uma variedade de tarefas restritas de IA. Espera-se que o tamanho do mercado de visão de IA atinja US$ 48,6 bilhões em 2022 e atinja US$ 144 bilhões até 2028. Considera-se que a visão computacional moldará a nova tecnologia UX mundial, onde computadores de bolso em smartphones, gadgets, wearables e ' as coisas terão uma visão semelhante à humana e uma inteligência superior.
Este artigo discutirá como funcionam os sistemas de visão computacional de última geração e por que a visão computacional é cada vez mais importante.
O que é visão computacional?
A visão computacional é um campo da inteligência artificial que trata do treinamento de computadores para perceber e compreender informações visuais de imagens, vídeos e outras entradas visuais. A visão da IA é considerada tão natural quanto a visão humana. Porém, ambos são muito diferentes um do outro. Estima-se que o olho humano tenha uma resolução de 576 megapixels, e toda essa carga de informações visuais é processada e analisada por uma rede altamente complexa de neurônios cerebrais. Mesmo os supercomputadores estão muito atrás em velocidade computacional em comparação com os neurônios cerebrais, e as câmeras mais avançadas não têm uma resolução correspondente à do olho humano.
É bastante trivial capturar informações visuais em imagens, vídeos ou transmissões ao vivo usando câmeras e sensores quando se trata de visão computacional. O verdadeiro desafio é obter insights e inferências significativas a partir dos dados visuais capturados computacionalmente. É aqui que o aprendizado de máquina e o aprendizado profundo são utilizados. O mundo real é infinitamente complexo e variado, de modo que um sistema de visão computacional só poderá ter sucesso se for capaz de aprender a partir de informações visuais.
Se a visão humana é uma obra-prima evolucionária, a visão computacional tem suas vantagens. As câmeras podem capturar dados visuais com melhor eficiência do que os olhos humanos. Eles também podem capturar informações visuais que não podem ser acessadas pelos olhos humanos, como imagens térmicas, exames médicos e outras tecnologias de imagem. Os sistemas de visão computacional podem ser projetados para serem mais específicos, precisos e exatos do que a visão humana. Por exemplo, os modelos de reconhecimento facial profundo alcançaram uma precisão de detecção de 99,63% em comparação com a precisão humana de 97,53%.
Tarefas de visão computacional
Antes de saber como funciona um sistema de visão computacional, é importante estar familiarizado com as tarefas comuns de visão computacional. Essas tarefas simples de percepção visual ajudam a segregar uma aplicação em grande escala em declarações de problemas mais diretas. Cada tarefa requer alguma funcionalidade cognitiva para sua execução.
- Classificação de imagens: A classificação de imagens é uma tarefa fundamental em aplicações de visão computacional. Envolve treinar uma rede neural para classificar imagens por categorias predefinidas. Isso geralmente envolve classificação por objetos específicos. Por exemplo, esta é a imagem de um gato, a imagem de um cachorro. Se a classificação tiver que ser feita entre apenas dois objetos, isso é chamado de problema de classificação binária. Se a classificação tiver que ser feita entre vários objetos, isso é chamado de problema de multiclassificação. Em um problema de classificação de imagens, a imagem inteira é processada como um todo e uma classe/rótulo exclusivo é atribuída a uma determinada imagem.
A classificação de imagens é um problema de aprendizagem supervisionada. O modelo é treinado para classificar imagens usando um conjunto de imagens de amostra já marcadas/classificadas. Feito o treinamento, um grupo de imagens deve ser classificado por rótulos/classes predefinidos. Um modelo de classificação de imagens pode facilmente ser ajustado sem dados de treinamento suficientes. É por isso que a aprendizagem por transferência ou transferência de conhecimento é frequentemente usada em modelos de classificação de imagens. Um modelo de aprendizado de máquina já treinado é reutilizado para classificar objetos semelhantes no método de aprendizagem por transferência. Isso permite a construção de soluções escalonáveis com um pequeno espaço computacional. A classificação de imagens é frequentemente chamada de classificação de objetos no jargão da IA.

- A detecção de objetos é a primeira etapa na extração de recursos de uma imagem. Embora a classificação de imagens se limite à categorização de imagens em classes exclusivas, a detecção de objetos envolve a análise de partes da imagem para localizar objetos nelas usando caixas delimitadoras. Isso é feito procurando detalhes específicos da classe em uma imagem, localizando objetos/classes na imagem/vídeo e rotulando-os por seus nomes de classe. Uma imagem pode conter vários objetos e um modelo de detecção de objetos pode procurar várias classes dentro de uma imagem.
A detecção de objetos é usada em problemas de visão computacional, como identificação de objetos, verificação de objetos e reconhecimento de objetos. Em comparação com abordagens de aprendizado de máquina como SIFT, recursos HOG e recursos Haar, modelos de aprendizado profundo como RCNN, YOLO, SSD e MobileNet são mais precisos e eficientes em tarefas de detecção de objetos.

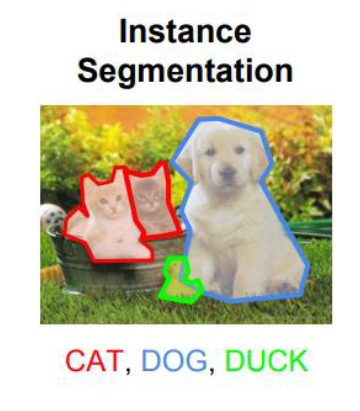
- Segmentação de imagem: envolve o mascaramento exato de pixels que representam um objeto dentro de uma imagem. Isso requer discernir o objeto de seu fundo e de outros objetos na imagem. Vários métodos de aprendizado de máquina e aprendizado profundo são usados para segmentação de imagens. Os métodos comuns de aprendizado de máquina aplicados à segmentação de imagens incluem agrupamento, bacia hidrográfica, detecção de bordas, crescimento de região, divisão e mesclagem de região e limite. Os modelos típicos de aprendizagem profunda usados para segmentação de imagens incluem FPN, SegNet, PSPNet e U-Net.
- Detecção de pontos de referência de objetos: é semelhante à segmentação de imagens. Em vez do objeto em si, nesta tarefa é identificado o seu contexto ou marco. Isso envolve discernir o plano de fundo do objeto na imagem e atribuir uma classe ao plano de fundo em vez do objeto.
- Detecção de bordas: Nesta tarefa, os limites de um objeto são detectados na imagem. Freqüentemente, esta é uma etapa de pré-processamento na segmentação de imagens executada internamente por um filtro especializado de detecção de bordas dentro de uma rede de convolução. Em muitos sistemas de visão computacional, isso faz parte do pré-processamento de imagens, onde a detecção de bordas é realizada aplicando um algoritmo de aprendizado de máquina.

- Extração e correspondência de recursos: recursos são os indicadores internos de um objeto. A extração de recursos envolve a identificação das partes de um objeto. Isso é bastante útil na detecção de objetos, estimativa de pose e problemas de calibração de câmera. Primeiro, as características de interesse são detectadas em uma imagem usando detecção de bordas ou outros métodos de extração de características. Isto é seguido pela localização desses recursos com a ajuda de descritores locais. Finalmente, os recursos e seus descritores locais são combinados entre um grupo de imagens para correspondência de recursos.
- Reconhecimento facial: Este tipo de tarefa de detecção de objetos em que o objeto a ser detectado ou reconhecido é um rosto humano único. Numa tarefa de reconhecimento facial, as características de uma imagem são extraídas, localizadas, classificadas e combinadas para derivar uma classificação exclusiva da própria imagem. Por exemplo, características faciais como olhos, nariz, boca, orelhas são identificadas, localizadas na imagem, posições comparadas com um modelo matemático absoluto e características são combinadas para realizar a identificação de uma pessoa.

- Reconhecimento óptico de caracteres: Nesta tarefa de visão computacional, os caracteres de um idioma devem ser identificados em uma imagem. Podem ser imagens de placas de matrícula ou notas manuscritas. OCR envolve a segmentação de imagens em letras de um idioma e geralmente é acompanhado pela codificação significativa de texto para uma determinada aplicação.
- Restauração de imagens: Esta tarefa envolve restaurar imagens antigas para recuperar sua qualidade e/ou adicionar cores a fotos antigas em preto e branco. Isso é feito reduzindo o ruído aditivo na imagem e realizando a pintura interna da imagem para restaurar pixels ou partes danificadas da imagem. Isso pode seguir a colorização da imagem em fotos em preto e branco.

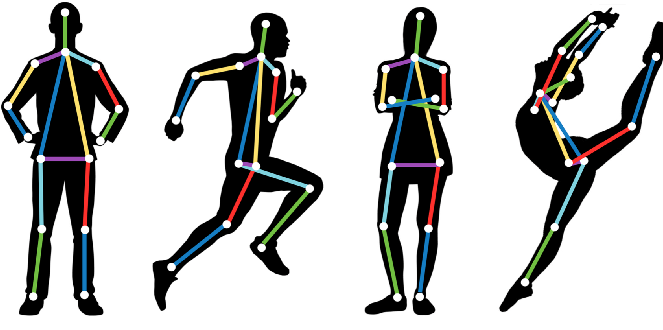
- Estimativa de pose: Nesta tarefa de visão computacional, a postura de um objeto/humano é identificada. Isso envolve a identificação de recursos, sua localização na imagem e a comparação das posições localizadas dos recursos entre si na imagem. Modelos comuns de aprendizado profundo usados para detecção de pose incluem PoseNet, MeTRAbs, OpenPose e DensePose.
- Análise de movimento de vídeo: Esta tarefa de visão computacional envolve traçar a trajetória de um objeto em um fluxo de vídeo ou câmera e determinar sua velocidade, caminho e movimento. Esta tarefa muito complicada envolve detecção de objetos, segmentação, localização, estimativa de pose e rastreamento em tempo real.
- Reconstrução de cena: Esta é a tarefa mais complexa em visão computacional. Envolve uma reconstrução 3D de um objeto a partir de imagens ou vídeos 2D.
Como funciona a visão computacional
Um sistema de visão computacional tem três níveis de operação, como segue.
- Aquisição de imagens: Em primeiro lugar, um sistema de visão computacional adquire imagens ou vídeos ou outras formas de entrada visual (como varreduras) de uma câmera ou sensor. As imagens/vídeo/streams capturados são transferidos para um sistema de computador armazenado para processamento posterior.
- Processando as imagens: As imagens brutas precisam ser preparadas para representar dados apropriados. Isso é feito pré-processando imagens, como redução de ruído, ajuste de contraste, redimensionamento e corte das imagens. A maioria desses trabalhos é automatizada dentro de um sistema de visão computacional. Algumas dessas etapas já são executadas no nível do hardware. Em contraste, outros são realizados utilizando filtros adequados dentro de uma rede de convolução ou aplicando funções de processamento de imagem adequadas aos dados brutos capturados.
- Compreendendo imagens: Esta é a parte mais importante de um sistema de visão computacional. É a implementação da tarefa real de visão computacional usando um estilo convencional de processamento de imagem ou com a ajuda de um modelo de aprendizagem profunda.
A inteligência artificial tornou obsoleto o estilo convencional de processamento de imagens na visão computacional. A rede de aprendizagem profunda é uma receita certa para qualquer problema de visão computacional.
O primeiro passo para entender as imagens é a engenharia de recursos. As imagens capturadas são convertidas em matrizes de pixels. As imagens levam muitos dados para sua representação computacional, e as imagens coloridas necessitam de uma boa memória para seu armazenamento e interpretação dentro de um modelo. Seguindo uma apresentação computacional adequada das imagens, as partes das imagens são identificadas como objetos usando bolhas, bordas e cantos. Este é um processo que exige muito da CPU e é demorado. É por isso que a detecção de objetos é automatizada usando aprendizagem por transferência. Grandes empresas que trabalham com visão computacional e IA compartilharam seus conjuntos de dados e modelos de aprendizagem profunda como ativos de código aberto para facilitar e automatizar o processo de detecção de objetos em imagens.
Isto é seguido pelo treinamento das redes de convolução para as tarefas específicas do domínio. Cada aplicação/tarefa de visão computacional requer um conjunto de dados específico. Por exemplo, uma aplicação de monitorização de tráfego necessitará de um conjunto de dados para identificar e classificar veículos. Um aplicativo de detecção de câncer precisará de um conjunto de dados de exames e relatórios médicos. A forma como um conjunto de dados é utilizado para treinar um modelo de rede neural depende das tarefas de visão computacional envolvidas na aplicação específica. Consequentemente, modelos apropriados de aprendizagem profunda são aplicados e as métricas de desempenho associadas são monitoradas.
Desafios em visão computacional
Existem vários desafios em aplicações de visão computacional. Freqüentemente, esses desafios estão relacionados à aquisição de imagens, engenharia de recursos ou interpretação dos dados visuais. Por exemplo, a diferença de iluminação comprometerá naturalmente uma aplicação de visão computacional que depende da identificação das cores ou imagem do objeto. A presença de ruído ou características indesejadas nas imagens é outro problema comum em aplicações de visão computacional. Devido a circunstâncias da vida real, esses recursos ou ruídos indesejáveis são frequentemente adicionados às imagens/vídeos. Por exemplo, as imagens capturadas por uma câmera de vigilância ficam desfocadas devido à chuva ou tempestades de poeira. Da mesma forma, objetos sobrepostos em uma imagem são sempre difíceis de identificar.
Outro conjunto de desafios aparece na seleção da engenharia de recursos. O mundo físico é tão variado e versátil que a escolha dos recursos apropriados para extração e correspondência em uma determinada aplicação pode se tornar uma tarefa difícil. Por exemplo, o mesmo objeto parece diferente de ângulos diferentes. A mesma classe de objeto pode ter uma variedade de cores e características internas. Por exemplo, um gato pode parecer diferente sob diferentes ângulos de visão; gatos da mesma raça têm cores e manchas de pele diferentes, e gatos de raças diferentes têm características corporais semelhantes, mas diferentes. Portanto, um modelo de aprendizado profundo deve receber imagens do objeto de diferentes ângulos e diferentes variações para evitar subajuste. É até possível que dois objetos tenham características e semelhanças semelhantes, resultando em semelhanças falsas. É por isso que são necessárias milhares ou milhões de imagens para treinar uma rede de aprendizagem profunda para identificar um objeto. Isso geralmente envolve detectar e combinar centenas de recursos para a mesma classe/rótulo.
Finalmente, um sistema de visão computacional pode falhar devido à interpretação inadequada ou insuficiente dos dados visuais. Isso geralmente acontece devido à falta de contexto ou inteligência geral em redes de visão computacional. Afinal, os sistemas de visão computacional dependem da identificação de padrões em imagens. Eles podem interpretar imagens apenas no contexto que lhes é fornecido ou dentro dos limites do conjunto de recursos utilizados na engenharia de recursos. As redes de aprendizagem profunda podem derivar representações significativas dos objetos/classes por meio da convolução, mas não podem gerar contextos e referências.
Conclusão
As redes neurais convolucionais trouxeram uma revolução no campo da visão computacional. A visão mecânica também passou da nuvem para a computação de ponta com os avanços da tecnologia computacional. Dotada de inteligência artificial e tecnologia sofisticada de chips, a visão computacional é agora aplicável em muitos domínios. O desenvolvimento da visão computacional e da inteligência artificial continuará de mãos dadas. A visão computacional já evoluiu além de sua capacidade limitada. O seu futuro reside em novos desenvolvimentos na área da inteligência artificial geral.







